O Realce de Sintaxe é o que faz com que o editor exiba automaticamente o texto em diferentes cores/estilos, dependendo da função da string em questão para o propósito do arquivo. No código-fonte do programa, por exemplo, declarações de controle pode ser renderizadas em negrito, enquanto tipos de dados e comentários ficam com cores diferentes do restante do texto. Isto aumenta consideravelmente a legibilidade do texto e assim, o autor pode ser mais eficiente e produtivo.

Uma função C++, representada com realce de sintaxe.

A mesma função C++, sem realce de sintaxe.
Dos dois exemplos, qual é o mais fácil de ler?
O KatePart vem com um sistema flexível, configurável e capaz de fazer realce de sintaxe; a distribuição padrão oferece definições para um vasto conjunto de linguagens de programação, de manipulação e de 'scripting', bem como para outros formatos de texto. Além disso, você pode criar as suas próprias definições em arquivos XML simples.
O KatePart detectará automaticamente regras de realce de sintaxe quando você abrir um arquivo, baseado no tipo MIME do arquivo, determinado pela extensão ou, se não existir, pelo conteúdo. Se você não conseguir, ajuste manualmente a sintaxe para o uso no menu → .
Os estilos e cores usados por cada definição de realce de sintaxe podem ser configurados usando a página de Estilos de Realce de Texto da Janela de Configuração; por outro lado, os tipos MIME e as extensões de arquivos para os quais deve ser usada, podem ser configurados usando a página de Modos & Tipos de Arquivo.
Nota
O realce de sintaxe existe para aumentar a legibilidade do texto correto, mas não se pode confiar nisto para validar seu texto. Marcar o texto para sintaxe é difícil, dependendo do formato que você está usando e, em alguns casos, os autores das regras de sintaxe ficarão orgulhosos se 98% do texto é renderizado corretamente, embora muito frequentemente você precise de um estilo raro para ver os 2% incorretos.
Esta seção irá discutir o realce de sintaxe do KatePart em detalhes. É para você, caso deseje saber mais sobre esta funcionalidade ou se quiser criar ou alterar as definições de sintaxe.
Sempre que você abrir um arquivo, uma das primeiras coisas que o editor KatePart faz é detectar qual definição de sintaxe deve ser usada para o arquivo. Ao ler o texto do arquivo, e enquanto você digita no arquivo, o sistema de realce de sintaxe analisará o texto usando as regras definidas pela definição de sintaxe, e marcará no texto onde contexto e estilos diferentes iniciarem e finalizarem.
Quando você escrever no documento, o novo texto será analisado e marcado na hora, pois se você remover um caractere que está marcado como início ou fim de um contexto, o estilo em volta do texto modifica de acordo com ele.
As definições de sintaxe usadas pelo sistema de realce de sintaxe do KatePart são arquivos XML que contém
Regras para a detecção do texto inteiro, organizado em blocos de contexto
Listas de palavras-chave
Definições de Item de Estilo
Ao analisar o texto, as regras de detecção serão avaliadas na ordem em que foram definidas, e se o início da string atual coincidir com uma regra, o contexto relacionado será usado. O ponto de partida no texto é movido para o ponto final no local onde aquela regra coincide, e um novo loop de regras inicia, começando no contexto configurado pela regra relacionada.
As regras de detecção são o "coração" do sistema de detecção de sintaxe. Uma regra é uma string, um caractere ou uma expressão regular com a qual se faz a correspondência do texto a analisar. Contém informações sobre o estilo a ser usado na parte correspondente do texto. Pode mudar do contexto atual do sistema para outro contexto explícito ou para o contexto anterior usado pelo texto.
As regras são organizadas em grupos de contexto, sendo que este é usado pelos conceitos principais do texto dentro de um formato, como por exemplo strings dentro de aspas ou blocos de comentário do código-fonte de um programa. Isto garante que o sistema de realce não precisa ficar procurando todas as regras quando não for necessário, e também que sequências de algum caractere no texto podem ser tratadas de modo diferente, dependendo do contexto atual.
As regras são organizadas em grupos de contexto, sendo que este é usado pelos conceitos principais do texto dentro de um formato, como por exemplo strings dentro de aspas ou blocos de comentário do código-fonte de um programa. Isto garante que o sistema de realce não precisa ficar procurando todas as regras quando não for necessário, e também que sequências de algum caractere no texto podem ser tratadas de modo diferente, dependendo do contexto atual.
Em algumas linguagens de programação, os números inteiros são tratados diferentemente dos números de ponto flutuante pelo compilador (o programa que converte o código-fonte para um binário executável), e podem existir caracteres que possuem significado especial dentro de uma string. Em tais casos, faz sentido renderizá-los de modo diferente dos outros, assim, são mais fáceis de identificar durante a leitura do texto. Mesmo que eles não sejam representados em contextos especiais, pode ser vistos no sistema de realce de sintaxe, e assim, podem ser marcados com uma renderização diferente.
Uma definição de sintaxe pode conter tantos estilos quanto forem necessários para cobrir os conceitos do formato no qual serão usados.
Em muitos formatos, existem listas de palavras, que representam um conceito específico; por exemplo, em linguagens de programação, as declaração de controle são um conceito, nomes de tipos de dados outro conceito, e funções pré-integradas na linguagem um terceiro conceito. O Sistema de Realce de Sintaxe do KatePart pode usar estas listas para detectar e marcar palavras no texto para enfatizar os conceitos dos formatos.
Se você abrir um arquivo de código em C++, um arquivo de Java™ e um documento em HTML no KatePart, irá ver que, ainda que os formatos sejam diferentes e, por isso, sejam selecionadas palavras diferentes para um tratamento especial, as cores usadas são as mesmas. Isto deve-se ao fato do KatePart ter uma lista pré-definida de Estilos Padrão, os quais são usados pelas definições de sintaxe individuais.
Isto faz com que fique mais fácil reconhecer conceitos similares em diferentes formatos. Por exemplo, os comentários estão presentes na maioria das linguagens de programação, script e marcação, e quando são renderizados utilizando-se o mesmo estilo em todas as linguagens, você não precisa parar e pensar para identificá-los dentro do texto.
Dica
Todos os estilos de uma definição de sintaxe usam um dos estilos padrão. Algumas definições de sintaxe usam mais estilos além dos pré-definidos, por isso se você usar um formato frequentemente, pode ser útil abrir a janela de configuração para ver se alguns conceitos usam o mesmo estilo. Por exemplo, só existe um estilo padrão para as cadeias de caracteres, mas como a linguagem de programação Perl lida com dois tipos de cadeias de caracteres, você pode melhorar o realce se configurar esses dois tipos de uma forma ligeiramente diferente. Todos os estilos padrão disponíveis serão explicados mais tarde.
O pacote KatePart utiliza o framework de realce de sintaxe do pacote KDE Frameworks™. Os arquivos XML de realce padrão fornecidos com o pacote KatePart são compilados na biblioteca de realce de sintaxe por padrão.
Esta seção é uma introdução ao formato XML de Definição de Realce. Baseado em um pequeno exemplo, ele irá descrever as componentes principais, bem como o seu significado e utilização. A próxima seção colocará em detalhes as regras de detecção.
A definição formal, também conhecida como XSD, você encontra no Repositório de realce de sintaxe no arquivo language.xsd
Os arquivos de definição de realce personalizados .xml estão localizados em org.kde.syntax-highlighting/syntax/ na sua pasta de usuário, encontrada com qtpaths que geralmente são --paths GenericDataLocation$HOME/.local/share//usr/share/.
Em pacotes Flatpak e Snap, o diretório acima não funcionará, pois o local dos dados é diferente para cada aplicativo. Em um aplicativo Flatpak, o local dos arquivos XML personalizados geralmente é $HOME/.var/app/nome-pacote-flatpak/data/org.kde.syntax-highlighting/syntax/$HOME/snap/nome-pacote-snap/current/.local/share/org.kde.syntax-highlighting/syntax/
No Windows, esses arquivos estão localizados em %USERPROFILE%\AppData\Local\org.kde.syntax-highlighting\syntax. %USERPROFILE% geralmente se expande para C:\Users\.user
Em resumo, para a maioria das configurações, o diretório de arquivos XML personalizados é o seguinte:
| Para o usuário local | |
| Para todos os usuários | /usr/share/org.kde.syntax-highlighting/syntax/ |
| Para pacotes Flatpak | |
| Para pacotes Snap | |
| No Windows® | %USERPROFILE%\AppData\Local\org.kde.syntax-highlighting\syntax |
| No macOS® | |
Se existirem vários arquivos para a mesma linguagem, o arquivo com o atributo de versão mais alto no elemento language será carregado.
Seções principais dos arquivos de Definições de Realce do KatePart
- Um arquivo de realce contém um cabeçalho que define a versão do XML:
<?xml version="1.0" encoding="UTF-8"?>
- A raiz do arquivo de definição é o elemento
language. Os atributos disponíveis são: Atributos necessários:
O
namedefine o nome da linguagem. Ele aparece nos respectivos menus e janelas.O
sectionindica a categoria.O
extensionsdefine as extensões dos arquivos, como por exemplo, "*.cpp;*.h"O
versionespecifica a revisão atual do arquivo de definição em termos de um número inteiro. Sempre que você alterar um arquivo de definição de realce, certifique-se de aumentar esse número.O
kateversionindica a última versão suportada pelo KatePart.Atributos opcionais:
O
mimetypeassocia os arquivos do tipo MIME.O
casesensitivedefine se as palavras-chave fazem distinção entre maiúsculas e minúsculas.O
priorityé necessário se outro arquivo de definições de realce usar as mesmas extensões. Ganhará o que tiver maior prioridade.O
authorcontém o nome do autor e o seu endereço de e-mail.O
licensecontém a licença, que é normalmente a licença MIT para novos arquivos de realce de sintaxe.O
stylecontém a linguagem fornecida e é usado pelos sistemas de recuo para o atributorequired-syntax-style.O
indenterdefine qual indentador será usado por padrão. Os indentadores disponíveis são: ada, normal, cstyle, cmake, haskell, latex, lilypond, lisp, lua, pascal, python, replicode, ruby e xml.O
hiddendefine se o nome deverá aparecer nos menus do KatePart.Assim, a próxima linha se parece com o seguinte:
<language name="C++" version="1" kateversion="2.4" section="Sources" extensions="*.cpp;*.h" />
- A seguir vem o elemento
highlighting, que contém o elemento opcionalliste os elementos obrigatórioscontextseitemDatas. O elemento
listcontém uma lista de palavras-chave. Neste caso, as palavras-chave são a class e a const.Você poderá adicionar tantas listas quanto desejar.Desde o KDE Frameworks™ 5.53, uma lista pode incluir palavras-chave de outra lista ou linguagem/arquivo, usando o elemento
include. O##é usado para separar o nome da lista e o nome da definição da linguagem, da mesma forma que na regraIncludeRules. Isso é útil para evitar a duplicação de listas de palavras-chave, caso você precise incluir as palavras-chave de outra linguagem/arquivo. Por exemplo, a lista othername contém a palavra-chave str e todas as palavras-chave da lista types, que pertence à linguagem ISO C++.O elemento
contextscontém todos os contextos. O primeiro contexto é, por padrão, o início do realce. Existem duas regras no contexto Normal Text (Texto Normal), que correspondem à lista de palavras-chave com o nome um_nome e uma regra que detecta aspas e muda o contexto para string (cadeia de caracteres). Para aprender mais sobre as regras, leia o próximo capítulo.A terceira parte é o elemento
itemDatas. Contém todas as cores e estilos de fonte necessários pelos contextos e regras. Neste exemplo, são usados oitemDatade Normal Text (Texto Normal), String (Cadeia de Caracteres) e Keyword (Palavra-Chave).<highlighting> <list name="somename"> <item>class</item> <item>const</item> </list> <list name="othername"> <item>str</item> <include>types##ISO C++</include> </list> <contexts> <context attribute="Normal Text" lineEndContext="#pop" name="Normal Text" > <keyword attribute="Keyword" context="#stay" String="somename" /> <keyword attribute="Keyword" context="#stay" String="othername" /> <DetectChar attribute="String" context="string" char=""" /> </context> <context attribute="String" lineEndContext="#stay" name="string" > <DetectChar attribute="String" context="#pop" char=""" /> </context> </contexts> <itemDatas> <itemData name="Normal Text" defStyleNum="dsNormal" /> <itemData name="Keyword" defStyleNum="dsKeyword" /> <itemData name="String" defStyleNum="dsString" /> </itemDatas> </highlighting>- A última parte de uma definição de realce é a seção opcional
general. Ela poderá conter informações sobre as palavras-chave, expansão/recolhimento de código, comentários, recuo, linhas vazias e verificação ortográfica. A seção
commentdefine com que texto é introduzido um comentário para uma única linha. Você poderá também definir comentários multilinha, usando o multiLine com o atributo adicional end. Isto é usado se o usuário pressionar o atalho correspondente para comentar/descomentar.A seção
keywordsdefine se as listas de palavras-chave fazem distinção entre maiúsculas e minúsculas ou não. Os outros atributos serão explicados mais tarde.As outras seções,
folding,emptyLinesespellchecking, geralmente não são necessárias e serão explicadas posteriormente.<general> <comments> <comment name="singleLine" start="#"/> <comment name="multiLine" start="###" end="###" region="CommentFolding"/> </comments> <keywords casesensitive="1"/> <folding indentationsensitive="0"/> <emptyLines> <emptyLine regexpr="\s+"/> <emptyLine regexpr="\s*#.*"/> </emptyLines> <spellchecking> <encoding char="á" string="\'a"/> <encoding char="à" string="\`a"/> </spellchecking> </general> </language>
Esta parte irá descrever todos os atributos disponíveis para o 'contexts', o 'itemDatas', o 'keywords', o 'comments', a expansão de código e o recuo.
- O elemento
contextpertence ao grupocontexts. Um contexto, por si só, define as regras específicas do contexto, como o que deve acontecer se o sistema de realce chegar ao fim de uma linha. Os atributos disponíveis são: O
namedeclara o nome do contexto. As regras irão usar esse nome para indicar o contexto para onde mudar, se a regra corresponder.O
attributeidentifica o estilo a ser usado para um caractere quando nenhuma regra corresponde ou quando uma regra não especifica um atributo. Neste último caso, o attribute do contexto especificado no context da regra será usado.O
lineEndContextdefine o contexto para onde o sistema de realce salta, se atingir o fim de uma linha. Poderá ser o nome de outro contexto, o#staypara não mudar de contexto (por exemplo, não fazer nada) ou o#popque fará com que saia deste contexto. É possível usar, por exemplo,#pop#pop#poppara sair de dentro de três contextos, ou ainda#pop#pop!OutroContextopara sair duas vezes e mudar para o contextoOutroContexto. Também é possível alternar para um contexto que pertence a outra definição de linguagem, da mesma forma que nas regrasIncludeRules, por exemplo,AlgumContexto##JavaScript. As mudanças de contexto também são descritas em “Regras de Detecção de Realce”. Padrão: #stay.O
lineEmptyContextdefine o contexto, se for encontrada uma linha em branco. A nomenclatura das mudanças de contexto é a mesma que a descrita anteriormente em lineEndContext. Padrão: #stay.O
fallthroughContextespecifica o próximo contexto para o qual alternar caso nenhuma regra corresponda. A nomenclatura das mudanças de contexto é a mesma descrita anteriormente em lineEndContext. Padrão: #stay.O
fallthroughdefine se o sistema de realce alterna para o contexto especificado emfallthroughContextcaso nenhuma regra corresponda. Observe que, desde o KDE Frameworks™ 5.62, este atributo está obsoleto em favor defallthroughContext, pois, se o atributofallthroughContextestiver presente, subentende-se implicitamente que o valor defallthroughé true. Padrão: false.O
noIndentationBasedFoldingdesativa o recolhimento baseado em indentação no contexto. Se o recolhimento baseado em indentação não estiver ativado, este atributo é inútil. Ele é definido no elemento folding do grupo general. Padrão: false.- O elemento
itemDataestá no grupoitemDatas. Define o estilo e as cores da fonte. Assim, é possível definir os seus próprios estilos e cores. Contudo, recomenda-se que usar os estilos predefinidos, para que o usuário veja sempre as mesmas cores usadas em várias linguagens. Todavia, existem casos em que não existe outra forma e, assim, é necessário mudar os atributos de cores e tipos de fonte. Os atributos 'name' e 'defStyleNum' são obrigatórios, enquanto os outros são opcionais. Os atributos disponíveis são: O
namedefine o nome do 'itemData'. Os contextos e regras irão usar este nome no seu atributo attribute, para referenciar um 'itemData'.O
defStyleNumdefine qual o estilo padrão usar. Os estilos pré-definidos disponíveis são explicados mais tarde em detalhes.O
colordefine uma cor. Os formatos válidos são o '#rrggbb' ou '#rgb'.O
selColordefine a cor da seleção.O
italic, se for true (verdadeiro), irá colocar o texto em itálico.O
bold, se for true (verdadeiro), irá colocar o texto em negrito.O
underline, se for true (verdadeiro), irá colocar o texto sublinhado.O
strikeOut, se for true (verdadeiro), o texto ficará traçado.O
spellChecking, se for true (verdadeiro), será verificada a ortografia do texto.- O elemento
keywords, no grupogeneral, define as propriedades das palavras-chave. Os atributos disponíveis são: O
casesensitivepoderá ser true (verdadeiro) ou false (falso). Se for true, todas as palavras-chave farão distinção entre maiúsculas e minúsculas.O
weakDeliminatoré uma lista de caracteres que não irão atuar como separadores de palavras. Por exemplo, o ponto'.'é um separador de palavras. Assuma que uma palavra-chave numlistcontém um ponto; nesse caso, só irá corresponder se indicar que o ponto é um delimitador fraco.O
additionalDeliminatordefine os delimitadores ou separadores adicionais.O
wordWrapDeliminatordefine os caracteres após os quais poderá ocorrer uma mudança de linha.Os delimitadores pré-definidos e de mudança de linha são os caracteres
.():!+,-<=>%&*/;?[]^{|}~\, o espaço (' ') e a tabulação ('\t').- O elemento
commentno grupocommentsdefine propriedades de comentário que são usadas para: → , → e → . Os atributos disponíveis são: O
nametanto poderá ser singleLine como multiLine. Se escolher o multiLine, serão necessários os atributos end e region. Se escolher singleLine, poderá adicionar o atributo opcional position.O
startdefine o texto usado para iniciar um comentário. No C++, este será o "/*" em comentários de várias linhas. Este atributo é obrigatório para os tipos multiLine e singleLine.O
enddefine o texto usado para fechar um comentário. No C++, será o "*/". Este atributo está disponível apenas e é obrigatório para comentários do tipo multiLine.O
regiondeverá ser o nome do comentário multi-linhas que poderá expandir ou recolher. Assuma que tem o beginRegion="Comment" ... endRegion="Comment" nas suas regras; nesse caso, deverá usar o region="Comment". Desta forma, a remoção de comentários funciona, mesmo que não tenha selecionado todo o texto do comentário multi-linhas. O cursor só precisa estar dentro deste comentário. Este atributo está disponível apenas para o tipo multiLine.O
positiondefine onde o comentário de linha única é inserido. Por padrão, o comentário de linha única é colocado no início da linha na coluna 0, mas se você usar position="afterwhitespace" o comentário é inserido após os espaços em branco iniciais à direita, antes do primeiro caractere que não seja um espaço em branco. Isso é útil para colocar comentários corretamente em linguagens onde a indentação é importante, como Python ou YAML. Este atributo é opcional e o único valor possível é afterwhitespace. Isso só está disponível para o tipo singleLine.- O elemento
folding, no grupogeneral, define as propriedades de dobragem/desdobramento do código. Os atributos disponíveis são: O
indentationsensitive, se for true, aplicará os marcadores de dobragem de código com base no recuo, como acontece na linguagem de programação Python. Normalmente você não terá que definir isto, uma vez que o valor padrão é false.- O elemento
emptyLineno grupoemptyLinesdefine quais linhas devem ser tratadas como linhas vazias. Isso permite modificar o comportamento do atributo lineEmptyContext nos elementoscontext. Os atributos disponíveis são: O
regexprdefine uma expressão regular que será tratada como uma linha em branco. Por padrão, linhas em branco não contêm nenhum caractere; portanto, isso adiciona linhas em branco adicionais, por exemplo, se você quiser que linhas com espaços também sejam consideradas linhas em branco. No entanto, na maioria das definições de sintaxe, você não precisa definir esse atributo.- O elemento
encodingno grupospellcheckingdefine uma codificação de caracteres para a verificação ortográfica. Atributos disponíveis: O
charé um caractere codificado.O
stringé uma sequência de caracteres que será codificada como o caractere char na verificação ortográfica. Por exemplo, na linguagem LaTeX, a string\"{A}representa o caractereÄ.
Os estilos padrão já foram explicados, em resumo: Os estilos padrão são os estilos de cores e fontes pré-definidos.
- Estilos padrão gerais:
dsNormal, quando não é necessário nenhum realce em especial.dsKeyword, para as palavras-chave do idioma incorporadas.dsFunction, nas chamadas e definições de funções.dsVariable, se aplicável: nomes das variáveis (por exemplo $algumaVariavel em PHP/Perl).dsControlFlow, palavras-chave de controle de fluxo, como o 'if', 'else', 'switch', 'break', 'return', 'yield', ...dsOperator, operadores como o + - * / :: < >dsBuiltIn, nas funções, classes e objetos incorporados.dsExtension, extensões comuns, como as classes e funções/macros do Qt™ em C++ e Python.dsPreprocessor, para as instruções do pré-processador ou para as definições de macros.dsAttribute, anotações como o @override e o __declspec(...).- Estilos padrão relacionados com as strings:
dsChar, para caracteres únicos, como o 'x'.dsSpecialChar, caracteres com significados especiais nas strings, como as sequências de escape, substituições ou operadores de expressões regulares.dsString, para strings do tipo "olá mundo".dsVerbatimString, strings literais como o 'raw \backlash' do Perl, CoffeeScript e das linhas de comando, assim como o r'\raw' do Python.dsSpecialString, SQL, expressões regulares, documentação, modo matemático do LATEX, ...dsImport, importação, inclusão ou requisição de módulos.- Estilos padrão relacionados com números:
dsDataType, para os tipos de dados incorporados, como o 'int', 'void', 'u64'.dsDecVal, nos valores decimais.dsBaseN, nos valores com uma base diferente de 10.dsFloat, nos valores de ponto flutuante.dsConstant, nas constantes incorporadas e definidas pelo usuário, como o PI.- Estilos padrão de comentários e relacionados com a documentação:
dsComment, para comentários.dsDocumentation, para /** Comentários de documentação */ ou """strings de documentação""".dsAnnotation, para os comandos de documentação como o @param, @brief.dsCommentVar, os nomes das variáveis usadas nos comandos acima, como o "foobar" no @param foobar.dsRegionMarker, para marcadores de região, como o //BEGIN, //END nos comentários.- Outros estilos padrão:
dsInformation, notas e dicas do tipo @note no doxygen.dsWarning, para os avisos do tipo @warning no doxygen.dsAlert, para palavras especiais como o TODO, FIXME, XXXX.dsError, para realçar erros e sintaxes inválidas.dsOthers, quando nada mais se aplica.
Esta seção descreve as regras de detecção de sintaxe.
Cada regra pode corresponder a zero ou mais caracteres no início do texto que é testado. Se a regra corresponder, é atribuído o estilo ou atributo definido pela regra aos caracteres correspondentes; uma regra poderá perguntar se o contexto atual será alterado.
As regras se parecem com isto:
<NomeRegra attribute="(identificador)" context="(identifier)" [atributos específicos da regra] />
O attribute identifica o estilo a usar para os caracteres correspondentes pelo nome ou índice; o context identifica, como esperado, o contexto a usar a partir daqui.
O context pode ser identificado por:
Um identificador, que é o nome do outro contexto.
Uma ordem diz ao mecanismo para ficar no contexto atual (
#stay), ou voltar a usar um contexto usado anteriormente na string (#pop). Um contexto vazio ou ausente é equivalente a#stay.Para voltar mais passos, a palavra-chave #pop pode ser repetida:
#pop#pop#popUma ordem seguida de um ponto de exclamação (!) e um identificador, que fará com que o mecanismo siga primeiro a ordem e depois mude para o outro contexto, por exemplo
#pop#pop!OtherContext.Um identificador, que é um nome de contexto, seguido por dois hashes (
##) e outro identificador, que é o nome de uma definição de linguagem. Essa nomenclatura é similar à usada nas regrasIncludeRulese permite que você alterne para um contexto pertencente a outra definição de realce de sintaxe, por exemplo,AlgumContexto##JavaScript.
Os atributos específicos da regra variam e estão descritos nas seções a seguir.
Atributos comuns
Todas as regras possuem os seguintes atributos em comum e estão disponíveis sempre que os (atributos comuns) aparecerem. Todos os atributos são opcionais.
attribute: Um atributo mapeia-se para um itemData definido. Padrão: attribute do contexto especificado no atributo context.
context: Indica o contexto para onde muda o sistema de realce, se a regra corresponder. Padrão: #stay.
beginRegion: Inicia um bloco de dobragem de código. Padrão: não definido.
endRegion: Fecha uma região de dobragem de código. Padrão: não definido.
lookAhead: Se for true (verdadeiro), o sistema de realce não irá processar o tamanho da correspondência. Padrão: false.
firstNonSpace: Corresponder apenas se o texto for o primeiro não-espaço em branco da linha. Padrão: false.
column: Corresponder apenas se a coluna corresponder. Padrão: não definido.
Regras dinâmicas
Algumas regras permitem o atributo opcional dynamic, do tipo booleano, cujo valor padrão é false. Se o 'dynamic' for true, uma regra poderá usar sequências de substituição que representam o texto correspondente a uma expressão regular que mudou para o contexto atual, nos seus atributos string ou char. Num string, o texto de substituição %N (em que o N é um número) será substituído pela captura correspondente a N na expressão regular de chamada, iniciando de 1. Num char, a sequência de substituição deverá ser um número N que será substituído pelo primeiro caractere da captura N da expressão regular de chamada. Sempre que uma regra permitir este atributo, irá conter um (dinâmico).
dynamic: poderá ser (true|false).
Como isto funciona:
Nas expressões regulares das regras RegExpr, todo o texto entre colchetes curvos simples (PADRÃO) é capturado e armazenado. Essas capturas podem ser usadas no contexto em que são alternadas, nas regras com o atributo dynamic true, por meio de %N (em String) ou N (em char).
É importante mencionar que um texto capturado em uma regra RegEx é armazenado apenas para o contexto alterado, especificado em seu atributo context.
Dica
Se as capturas não forem usadas, tanto por regras dinâmicas quanto na mesma expressão regular, grupos não capturantes devem ser usados:
(?:PADRÃO)Os grupos lookahead ou lookbehind, como
(?=PADRÃO),(?!PADRÃO)ou(?<=PADRÃO), não são capturados. Consulte Expressões regulares para obter mais informações.Os grupos de captura podem ser usados dentro da mesma expressão regular, usando
\Nem vez de%Nrespectivamente. Para mais informações, consulte Capturando texto correspondente (referências anteriores) em Expressões regulares.
Exemplo 1:
Neste exemplo simples, o texto correspondente à expressão regular =* é capturado e inserido em %1 na regra dinâmica. Isso permite que o comentário termine com a mesma quantidade de = que no início. Isso corresponde a textos como: [[ comentário ]], [=[ comentário ]=] ou [=====[ comentário ]=====].
Além disso, as capturas estão disponíveis apenas no contexto alternado para Comentário de várias linhas.
<context name="Normal" attribute="Normal Text" lineEndContext="#stay"> <RegExpr context="Multi-line Comment" attribute="Comment" String="\[(=*)\[" beginRegion="RegionComment"/> </context> <context name="Multi-line Comment" attribute="Comment" lineEndContext="#stay"> <StringDetect context="#pop" attribute="Comment" String="]%1]" dynamic="true" endRegion="RegionComment"/> </context>
Exemplo 2:
Na regra dinâmica, %1 corresponde à captura que corresponde a #+, e %2 a "+. Isso corresponde ao texto como:#label""""dentro do contexto""""#.
Essas capturas não estarão disponíveis em outros contextos, como OtherContext, FindEscapes ou SomeContext.
<context name="SomeContext" attribute="Normal Text" lineEndContext="#stay"> <RegExpr context="#pop!NamedString" attribute="String" String="(#+)(?:[\w-]|[^[:ascii:]])("+)"/> </context> <context name="NamedString" attribute="String" lineEndContext="#stay"> <RegExpr context="#pop!OtherContext" attribute="String" String="%2(?:%1)?" dynamic="true"/> <DetectChar context="FindEscapes" attribute="Escape" char="\"/> </context>
Exemplo 3:
Isso corresponde a textos como: Class::function<T>( ... ).
<context name="Normal" attribute="Normal Text" lineEndContext="#stay">
<RegExpr context="FunctionName" lookAhead="true"
String="\b([a-zA-Z_][\w-]*)(::)([a-zA-Z_][\w-]*)(?:<[\w\-\s]*>)?(\()"/>
</context>
<context name="FunctionName" attribute="Normal Text" lineEndContext="#pop">
<StringDetect context="#stay" attribute="Class" String="%1" dynamic="true"/>
<StringDetect context="#stay" attribute="Operator" String="%2" dynamic="true"/>
<StringDetect context="#stay" attribute="Function" String="%3" dynamic="true"/>
<DetectChar context="#pop" attribute="Normal Text" char="4" dynamic="true"/>
</context>
Delimitadores locais
Algumas regras permitem os atributos opcionais weakDeliminator e additionalDeliminator, que são combinados com atributos de mesmo nome da tag keywords. Por exemplo, quando '%' é um delimitador fraco de keywords, ele pode se tornar um delimitador de palavras apenas para uma regra ao ser inserido em seu atributo additionalDeliminator. Sempre que uma regra permite esses atributos, ela conterá um (delimitadores locais).
weakDeliminator: lista de caracteres que não atuam como delimitadores de palavras.
additionalDeliminator: define os delimitadores ou separadores adicionais.
- DetectChar
Detecta um caractere específico. Comumente usado, por exemplo, para encontrar o final das strings citadas.
<DetectChar char="(caractere)" (atributos comuns) (dinâmico) />
O atributo
chardefine o caractere a ser procurado.- Detect2Chars
Detecta dois caracteres específicos, em uma ordem definida.
<Detect2Chars char="(caractere)" char1="(caractere)" (atributos comuns) />
O atributo
chardefine o primeiro caractere a ser procurado, e o atributochar1o segundo.Esta regra existe por razões históricas e, para facilitar a leitura, é preferível usar
StringDetect.- AnyChar
Detecta um caractere de um conjunto de caracteres especificados.
<AnyChar String="(string)" (atributos comuns) />
O atributo
Stringdefine o conjunto de caracteres.- StringDetect
Detecta uma string exata.
<StringDetect String="(string)" [insensitive="true|false;"] (atributos comuns) (dinâmico) />
O atributo
Stringdefine a sequência a encontrar. O atributoinsensitiveé por padrão false e é passado à função de comparação de cadeias de caracteres. Se o valor for true a comparação não faz distinção entre maiúsculas e minúsculas.- WordDetect
Detecta um texto exato, mas obriga adicionalmente a que esteja rodeado por limites de palavras, como um ponto
'.'ou um espaço em branco no início e no fim da palavra. Pense em\b<texto>\bem termos de uma expressão regular, só que é mais rápido que a regraExp Reg.<WordDetect String="(string)" [insensitive="true|false;"] (atributos comuns) (delimitadores locais) />
O atributo
Stringdefine a sequência a encontrar. O atributoinsensitiveé por padrão false e é passado à função de comparação de cadeias de caracteres. Se o valor for true a comparação não faz distinção entre maiúsculas e minúsculas.Desde: Kate 3.5 (KDE 4.5)
- RegExpr
Procura por uma expressão regular.
<RegExpr String="(texto)" [insensitive="true|false"] [minimal="true|false"] (atributos comuns) (dinâmico) />
O atributo
Stringdefine a expressão regular.O
insensitiveé, por padrão, false e é passado ao motor de expressões regulares.O
minimalé, por padrão, false e é passado ao motor de expressões regulares.Pelo motivo que as regras estão sempre iniciando a busca no início da string atual, uma expressão regular iniciada com um acento circunflexo (
^) indica que a regra deve ser coincidente somente no início da linha.Veja em Expressões Regulares mais informações sobre o assunto.
- keyword
Detecta uma palavra-chave de uma lista especificada.
<keyword String="(nome da lista)" (atributos comuns) (delimitadores locais) />
O atributo
Stringidentifica a lista de palavras-chave pelo nome. Uma lista com aquele nome, portanto, deve existir.O sistema de realce processa as regras da palavra-chave de forma muito otimizada. Isto a torna uma necessidade absoluta em que quaisquer palavras-chave a corresponder sejam envolvidas por separadores definidos, sejam eles implícitos (os separadores padrão) ou explícitos, com a propriedade additionalDeliminator da marca keywords.
Se uma palavra-chave a corresponder conter um caractere separador, este caractere respectivo deverá ser adicionado à propriedade weakDeliminator da marca keywords. Este caractere irá então perder a sua propriedade de separador em todas as regras keyword. Também é possível usar o atributo weakDeliminator de keyword para que esta modificação se aplique apenas a esta regra.
- Int
Detecta um número inteiro (como a expressão regular:
\b[0-9]+).<Int (atributos comuns) (delimitadores locais) />
Esta regra não possui atributos específicos.
- Float
Detecta um número de ponto flutuante (como a expressão regular:
(\b[0-9]+\.[0-9]*|\.[0-9]+)([eE][-+]?[0-9]+)?).<Float (atributos comuns) (delimitadores locais) />
Esta regra não possui atributos específicos.
- HlCOct
Detecta uma representação de número de ponto octal (como a expressão regular:
\b0[0-7]+).<HlCOct (atributos comuns) (delimitadores locais) />
Esta regra não possui atributos específicos.
- HlCHex
Detecta uma representação numérica hexadecimal (como uma expressão regular:
\b0[xX][0-9a-fA-F]+).<HlCHex (atributos comuns) (delimitadores locais) />
Esta regra não possui atributos específicos.
- HlCStringChar
Detecta um caractere de escape.
<HlCStringChar (atributos comuns) />
Esta regra não possui atributos específicos.
Corresponde a representações literais dos caracteres usados normalmente no código do programa como, por exemplo, o
\n(nova linha) ou o\t(TAB).Os seguintes caracteres irão corresponder se estiverem após uma barra invertida (
\):abefnrtv"'?\. Além disso, os números escapados em hexadecimal como, por exemplo, o\xffe os números octais escapados, como o\033, irão corresponder.- HlCChar
Detecta um caractere do C.
<HlCChar (atributos comuns) />
Esta regra não possui atributos específicos.
Corresponde aos caracteres em C colocados dentro de um tique (Exemplo:
'c'). Os tiques podem ser um único caractere ou um caractere de escape. Veja o 'HlCStringChar' para ver as sequências de caracteres de escape correspondentes.- RangeDetect
Detecta uma string com os caracteres de início e fim definidos.
<RangeDetect char="(caractere)" char1="(caractere)" (atributos comuns) />
O
chardefine o caractere de início e ochar1o caractere que termina o intervalo.Útil para detectar, por exemplo, pequenas cadeias de caracteres entre aspas e semelhantes, mas repare que, uma vez que o motor de realce de sintaxe funciona com uma linha de cada vez, isto não irá encontrar as cadeias de caracteres que se prolonguem por mais de uma linha.
- LineContinue
Corresponde um caractere específico indicado no fim de uma linha.
<LineContinue (atributos comuns) [char="\"] />
O atributo
chardefine o caractere opcional a ser encontrado, sendo a barra invertida ('\'). o padrão. Novidade da versão 4.13 do KDE.Esta regra é útil para mudar de contexto no fim da linha. Isso é necessário no C/C++, por exemplo, para continuar as macros ou cadeias de caracteres.
- IncludeRules
Inclui as regras de outro contexto ou linguagem/arquivo.
<IncludeRules context="ligacao_contexto" [includeAttrib="true|false"] />
O atributo
contextdefine o contexto a incluir.Se for texto simples, inclui todas as regras definidas no contexto atual, como por exemplo:
<IncludeRules context="outroContexto" />
Se o texto conter um
##, o sistema de realce irá procurar por um contexto de outra definição de linguagem com o nome indicado, por exemplo,<IncludeRules context="String##C++" />
iria incluir o contexto String da definição de realce C++.
Se o atributo
includeAttribfor true, muda o atributo de destino para o da origem. Isto é necessário para fazer, por exemplo, funcionar os comentários, se o texto correspondente ao contexto incluído for de um realce diferente do contexto-anfitrião.- DetectSpaces
Detecta espaços em branco.
<DetectSpaces (atributos comuns) />
Esta regra não possui atributos específicos.
Use esta regra se souber que poderão existir vários espaços em branco à frente como, por exemplo, no início das linhas recuadas. Esta regra irá ignorar todos os espaços em branco, em vez de testar várias regras e ignorar uma de cada vez, devido a uma falta de correspondência.
- DetectIdentifier
Detecta os textos dos identificadores (como a expressão regular:
[a-zA-Z_][a-zA-Z0-9_]*).<DetectIdentifier (atributos comuns) />
Esta regra não possui atributos específicos.
Use esta regra para ignorar uma sequência de caracteres de palavras de uma vez, em vez de testar com várias regras e ignorar uma de cada vez, por falta de correspondência.
Logo que tenha compreendido como funciona a mudança de contexto, será fácil de criar definições de realce. Ainda que você deva verificar com cuidado a regra que escolher, dependendo da situação, as expressões regulares são muito poderosas, só que são lentas em comparação com as outras regras. Assim, você poderá considerar útil as seguintes dicas.
As expressões regulares são fáceis de usar mas, normalmente, existe outra forma muito mais rápida de obter o mesmo resultado. Assuma que só deseja corresponder com o caractere
'#'se for o primeiro caractere da linha. Uma solução baseada em expressões regulares seria semelhante à seguinte:<RegExpr attribute="Macro" context="macro" String="^\s*#" />
Você poderá obter o mesmo se usar:
<DetectChar attribute="Macro" context="macro" char="#" firstNonSpace="true" />
Se quiser corresponder à expressão regular
'^#', poderá usar ainda oDetectCharcom o atributocolumn="0". O atributocolumnconta como caracteres; assim, uma tabulação conta como se fosse apenas um caractere.Nas regras
RegExpr, use o atributocolumn="0"se o padrão^PADRÃOfor usado para encontrar correspondências no início de uma linha. Isso melhora o desempenho, pois evita a busca por correspondências nas demais colunas.Em expressões regulares, use grupos não capturantes
(?:PADRÃO)em vez de grupos capturantes(PADRÃO), se as capturas não forem usadas na mesma expressão regular ou em regras dinâmicas. Isso evita o armazenamento desnecessário de capturas.Você poderá mudar de contextos sem processar os caracteres. Assuma que deseja mudar de contexto quando encontrar o texto
*/, mas necessita de processar essa sequência no próximo contexto. A regra abaixo irá corresponder e o atributolookAheadfará com que o sistema de realce mantenha o texto correspondente no próximo contexto.<StringDetect attribute="Comment" context="#pop" String="*/" lookAhead="true" />
Use o
DetectSpacesse você souber que irão ocorrer vários espaços em branco.Use o
DetectIdentifierem vez da expressão regular'[a-zA-Z_]\w*'.Use os estilos padrão sempre que puder. Desta forma, o usuário irá encontrar um ambiente familiar.
Procure em outros arquivos XML para ver como as outras pessoas implementam as regras mais complicadas.
Você pode validar todos os arquivos XML usando o comando validatehl.sh mySyntax.xml. O arquivo
validatehl.shusalanguage.xsdque estão disponíveis no Repositório de realce de sintaxe.Se repetir algumas expressões regulares complexas com frequência, você poderá usar as ENTIDADES. Por exemplo:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE language [ <!ENTITY myref "[A-Za-z_:][\w.:_-]*"> ]>Agora, você poderá usar o &referencia; em vez da expressão regular.
No editor do Kate, você pode recarregar as sintaxes usando a linha de comando integrada (atalho
F7por padrão) e o comando reload-highlighting.Você pode usar o utilitário de linha de comando chamado
ksyntaxhighlighter6(kate-syntax-highlighterem versões mais antigas) para testar uma sintaxe e exibir o estilo e as regiões associadas a cada parte de um texto.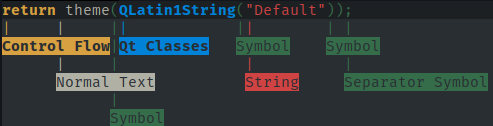
Resultado de ksyntaxhighlighter6 --output-format=ansi --syntax-trace=format test.cpp.
Use ksyntaxhighlighter6 -h para mais opções.