Accentuering van syntaxis zorgt er voor dat de tekstbewerker automatisch tekst in verschillende stijlen/kleuren laat zien, afhankelijk van de functie van de tekenreeks in relatie tot het doel van het bestand. In broncode voor programma's bijvoorbeeld, kunnen besturingsstatements vet worden weergegeven, terwijl typen gegevens en commentaar een andere kleur krijgen dan de rest van de tekst. Dit verbetert de leesbaarheid van de tekst enorm en helpt de auteur dus om efficiënter en productiever te zijn.

Een C++-functie, weergegeven met syntaxisaccentuering.

Dezelfde C++-functie, weergegeven zonder accentuering.
Welke van de twee voorbeelden is gemakkelijker te lezen?
KatePart komt met een flexibel, te configureren en capabel systeem voor accentuering van de syntaxis en de standaard distributie levert definities voor een brede reeks van programmeer-, script- en markup-talen en andere formaten van tekstbestanden. Bovendien kunt u uw eigen definities leveren in eenvoudige XML-bestanden.
KatePart zal automatisch de juiste syntaxisregels detecteren wanneer u een bestand opent, gebaseerd op het MIME-type van het bestand, bepaald door zijn extensie of, als deze er geen heeft, de inhoud. Ervaart u een foute keuze, dan kunt u handmatig de te gebruiken syntaxis instellen uit het menu → .
De stijlen en kleuren die door elke definitie voor syntaxisaccentuering kan worden ingesteld met het tabblad Accentuering van tekststijlen van de Instellingendialoog, terwijl de MIME-types en bestandsextensies waarvoor ze gebruikt zouden moeten worden, worden behandeld door het tabblad Modi & bestandstypen.
Opmerking
Syntaxisaccentuering is er om de leesbaarheid van correcte tekst te verhogen, maar u kunt het niet vertrouwen om uw tekst te valideren. Tekst markeren voor syntaxis is moeilijk, afhankelijk van het formaat dat u gebruikt en in sommige gevallen zullen de auteurs van de syntaxisregels trots zijn als 98% van de tekst juist wordt weergegeven, hoewel u meestal een zeldzame stijl nodig hebt om de onjuiste 2% tegen te komen.
Deze sectie zal het mechanisme voor syntaxisaccentuering van KatePart in meer detail laten zien. Het is er voor u als u er iets over wilt weten of als u syntaxis-definities wilt veranderen of aanmaken.
Wanneer u een bestand opent, is een van de eerste dingen die de tekstbewerker KatePart doet, het detecteren van welke syntaxis-definitie voor het bestand moet worden gebruikt. Terwijl de tekst van het bestand wordt ingelezen en terwijl u het intypt, zal het systeem voor syntaxisaccentuering de tekst analyseren met de regels gedefinieerd door de syntaxis-definitie en het markeren waar verschillende contexten en stijlen beginnen en eindigen.
Tijdens het typen van het document wordt de nieuwe tekst geanalyseerd en direct gemarkeerd, zodat wanneer u een teken verwijdert die is gemarkeerd als het begin van einde van een context, de stijl van de tekst er omheen overeenkomstig wijzigt.
De syntaxis-definities die door het systeem voor syntaxisaccentuering van KatePart wordt gebruikt zijn XML-bestanden, bevattende
Regels voor detecteren van de rol van tekst, georganiseerd in contextblokken
Lijsten met sleutelwoorden
Definities van stijl-items
Bij het analyseren van de tekst worden de detectieregels geëvalueerd in de volgorde waarin ze zijn gedefinieerd en, als het begin van de huidige tekenreeks overeenkomt met een regel, wordt de gerelateerde context gebruikt. Het beginpunt in de tekst wordt verplaatst naar het eindpunt waarop die regel overeenkomt en een nieuwe ronde van de regels begint, beginnend in de context ingesteld door de overeenkomende regel.
De detectieregels zijn het hart van het detectiesysteem voor accentuering. Een regel is een tekenreeks, teken of reguliere expressie waartegen de tekst die wordt geanalyseerd wordt vergeleken. Het bevat informatie over welke stijl te gebruiken voor het overeenkomende deel van de tekst. Het kan de in werking zijnde context van het system omschakelen ofwel naar een expliciet genoemde context of naar de vorige context in gebruik bij de tekst.
Regels zijn georganiseerd in contextgroepen. Een contextgroep wordt gebruikt voor hoofdtekstconcepten in het formaat, bijvoorbeeld tekenreeksen tussen aanhalingstekens of commentaarblokken in broncode van programma's. Dit zorgt ervoor dat het accentueringssysteem niet door alle regels hoeft te doorlopen wanneer het niet noodzakelijk is en dat sommige tekenreeksen in de tekst anders kan worden behandeld afhankelijk van de huidige context.
Contexts kunnen dynamisch worden gegenereerd om het gebruik van specifieke gegevens bij toestanden in regels toe te staan.
In sommige programmeertalen worden door de compiler (het programma dat de broncode vertaald in een binair uitvoerbaar programma) gehele getallen anders behandeld dan drijvendekommagetallen en er kunnen tekens zijn met een speciale betekenis in een tekenreeks tussen aanhalingsteken. In zulke gevallen, is het zinvol om ze verschillend weer te geven in hun omgeving zodat ze gemakkelijk zijn te identificeren bij het lezen van de tekst. Dus zelfs als ze speciale contexts representeren, kunnen ze als zodanig door het systeem voor accentuering van syntaxis worden gezien, zodat ze gemarkeerd kunnen worden voor een anders weergeven.
Een syntaxis-definitie kan zoveel stijlen bevatten als nodig is om de concepten van het formaat te dekken waarvoor het wordt gebruikt.
In vele formaten zijn er lijsten woorden die een specifiek concept representeren. Bijvoorbeeld in programmeertalen, zijn controlstatements een concept, namen van gegevenstypen een andere en ingebouwde functies van de taal een derde. Het accentueringssysteem voor syntaxis van KatePart kan zulke lijsten gebruiken om woorden in de tekst te detecteren en te markeren om concepten te accentueren van de tekstformaten.
Als u in KatePart een C++ bronbestand, een Java™ bronbestand en een HTML-document opent, dan zult u zien dat zelfs wanneer de formaten verschillend zijn en dus verschillende woorden voor een speciale behandeling worden gekozen, de gebruikte kleuren hetzelfde zijn. Dit komt omdat KatePart een voorgedefinieerde lijst met standaard stijlen heeft die worden gebruikt bij de individuele definities van syntaxis.
Dit maakt het gemakkelijk om gelijkvormige concepten in verschillende tekstformaten te herkennen. Bijvoorbeeld: commentaar is in bijna elk programma, script of markup-language aanwezig en wanneer ze in alle talen op dezelfde manier worden weergegeven, dan hoeft u niet meer na te denken om ze in de tekst te herkennen.
Tip
Alle stijlen in een syntaxisdefinitie gebruiken een van de standaard stijlen. Een paar syntaxisdefinities gebruiken meer stijlen dan er standaarden zijn, dus als u een format vaak gebruikt kan het het waard zijn om de instellingendialoog te starten om te zien of sommige concepten dezelfde stijl gebruiken. Er is bijvoorbeeld slechts één standaard stijl voor tekenreeksen, maar de Perl programmeertaal werkt met twee typen tekenreeksen, u kunt het accentueren verbeteren door ze enigszins verschillend in te stellen. Alle beschikbare standaard stijlen zullen later worden verklaard.
KatePart gebruikt het framework voor accentuering van sysntaxis uit KDE Frameworks™. De standaard XML-bestanden voor accentuering geleverd met KatePart zijn standaard gecompileerd in de bibliotheek voor accentuering van syntaxis.
Deze sectie is een overzicht van het formaat van 'Highlight Definition XML'. Het zal de hoofdcomponenten, hun betekenis en gebruik beschrijven op basis van een klein voorbeeld. De volgende sectie zal in detail de accentueringdetectieregels uitleggen.
De formele definitie, ook bekend als XSD kunt u vinden in Opslagruimte voor accentuering van syntaxis in het bestand taal.xsd
Zelf gemaakte .xml bestanden voor definitie van accentuering zijn geplaatst in org.kde.syntax-highlighting/syntax/ in uw gebruikersmap te vinden met qtpaths die gebruikelijk--paths GenericDataLocation$HOME/.local/share//usr/share/ zijn.
Voor pakketten uit Flatpak en Snap zal de bovenstaande map niet werken omdat de gegevenslocatie verschillend is voor elke toepassing. In een Flatpak toepassing is de locatie van aangepaste XML-bestanden gewoonlijk $HOME/.var/app/flatpak-pakketnaam/data/org.kde.syntax-highlighting/syntax/$HOME/snap/snap-pakketnaam/current/.local/share/org.kde.syntax-highlighting/syntax/
Op Windows® zijn deze bestanden gelokaliseerd in %USERPROFILE%\AppData\Local\org.kde.syntax-highlighting\syntax. %USERPROFILE% wordt gewoonlijk C:\Users\.gebruiker
Samenvattend, voor de meeste configuraties is de map met aangepaste XML-bestanden als volgt:
| Voor lokale gebruiker | |
| Voor alle gebruikers | /usr/share/org.kde.syntax-highlighting/syntax/ |
| Voor Flatpak pakketten | |
| Voor Snap pakketten | |
| Op Windows® | %USERPROFILE%\AppData\Local\org.kde.syntax-highlighting\syntax |
| Op macOS® | |
Als meerdere bestanden bestaan voor dezelfde taal zal het bestand met het hoogste versie-attribuut in het taal-element worden geladen.
Hoofdsecties van bestanden voor accentueringsdefinities van KatePart
- Een bestand voor accentuering bevat een kop die de XML-versie instelt:
<?xml version="1.0" encoding="UTF-8"?>
- De basis van het definitiebestand is het element
language. Beschikbare attributen zijn: Vereiste attributen:
namestelt de naam van de taal in. Het verschijnt nadien in de menu's en dialogen.sectionspecificeert de categorie.extensionsdefinieert bestandsextensies, zoals "*.cpp;*.h"versiespecificeert de huidige revisie van het definitiebestand in termen van een geheel getal. Wanneer u een geaccentueerd definitiebestand wijzigt, verzeker u ervan dat dit getal wordt verhoogt.kateversionspecificeert de laatst ondersteunde versie van KatePart.Optionele attributen:
mimetypeassocieert ket MIME-type van bestanden.casesensitivedefinieert of de sleutelwoorden gevoelig zijn voor hoofd- en kleine letters.priorityis nodig als een andere bestand met accentueringsdefinities dezelfde extensies gebruiken. De hogere prioriteit wint.authorbevat de naam van de auteur en zijn/haar e-mailadres.licensebevat de licentie, gewoonlijk de MIT licentie voor nieuwe bestanden met accentuering van syntaxis.stylebevat de geleverde taal en wordt gebruikt door de indenteerders voor het attribuutrequired-syntax-style.indenterdefinieert welke indenteerder standaard gebruikt zal worden. Beschikbare indenterders zijn: ada, normal, cstyle, cmake, haskell, latex, lilypond, lisp, lua, pascal, python, replicode, ruby en xml.hiddendefinieert of de naam moet verschijnen in de menu's van KatePart.De volgende regel kan er als volgt uitzien:
<language name="C++" version="1" kateversion="2.4" section="Sources" extensions="*.cpp;*.h" />
- Vervolgens komt het element
highlighting, die het optionele elementlistbevat en de vereiste elementencontextsenitemDatas. Elementen
listbevatten een lijst met sleutelwoorden. In dit geval zijn de sleutelwoorden class en const. U mag zoveel elementen 'list' toevoegen als nodig is.Sinds KDE Frameworks™ 5.53 kan een lijst sleutelwoorden uit een andere lijst of taal/bestand invoegen met gebruik van het element
include.##wordt gebruikt om de naam van de lijst en de naam van de taaldefinitie te scheiden, op dezelfde manier als in de regelIncludeRules. Dit is nuttig om duplicaten van lijsten met sleutelwoorden te vermijden, als u het nodig hebt om de sleutelwoorden van een andere taal/bestand in te voegen. De lijst anderenaam bevat het sleutelwoord str en alle sleutelwoorden van de lijst types, die behoren bij de taal ISO C++.Het element
contextsbevat alle contexten. De eerste context is per definitie het begin van de accentuering. Er zijn twee regels in de context Normal Text, die overeenkomt met de lijst sleutelwoorden met de naam somename en een regel die een aanhalingsteken detecteert en de context om schakelt naar String. Om meer over regels te leren, leest u het volgende hoofdstuk.Het derde deel is het element
itemDatas. Het bevat alle kleur- en lettertypestijlen nodig voor de contexten en regels. In dit voorbeeld wordenitemDataNormal Text, String en Keyword gebruikt.<highlighting> <list name="eennaam"> <item>class</item> <item>const</item> </list> <list name="othername"> <item>str</item> <include>types##ISO C++</include> </list> <contexts> <context attribute="Normal Text" lineEndContext="#pop" name="Normal Text" > <keyword attribute="Keyword" context="#stay" String="eennaam" /> <keyword attribute="Keyword" context="#stay" String="anderrnaam" /> <DetectChar attribute="String" context="string" char=""" /> </context> <context attribute="String" lineEndContext="#stay" name="string" > <DetectChar attribute="String" context="#pop" char=""" /> </context> </contexts> <itemDatas> <itemData name="Normal Text" defStyleNum="dsNormal" /> <itemData name="Keyword" defStyleNum="dsKeyword" /> <itemData name="String" defStyleNum="dsString" /> </itemDatas> </highlighting>- Het laatste deel van een definitie voor accentuering is de optionele sectie
general. Het mag informatie over sleutelwoorden, invouwen van code, commentaar, inspringen, lege regels en spellingcontrole bevatten. De sectie
commentdefinieert met welke tekenreeks een enkele regel commentaar wordt aangegeven. U kunt ook commentaar op meerdere regels definiëren met multiLine met het additionele attribuut end. Dit wordt gebruikt als de gebruiker op de bijbehorende sneltoets voor comment/uncomment drukt.De sectie
keywordsdefinieert of lijsten met sleutelwoorden onderscheid maken tussen hoofd- en kleine letters. Andere attributen zullen later worden verklaard.De andere secties,
folding,emptyLinesenspellcheckingzijn gewoonlijk niet nodig en worden later uitgelegd.<general> <comments> <comment name="singleLine" start="#"/> <comment name="multiLine" start="###" end="###" region="CommentFolding"/> </comments> <keywords casesensitive="1"/> <folding indentationsensitive="0"/> <emptyLines> <emptyLine regexpr="\s+"/> <emptyLine regexpr="\s*#.*"/> </emptyLines> <spellchecking> <encoding char="á" string="\'a"/> <encoding char="à" string="\`a"/> </spellchecking> </general> </language>
Dit deel zal alle beschikbare attributen voor contexten beschrijven, itemDatas, sleutelwoorden, commentaar, code opvouwen en inspringen.
- Het element
contextbehoort tot de groepcontexts. Een context zelf definieert context specifieke regels zoals wat zou moeten gebeuren als het systeem voor accentuering het eind van een regel bereikt. Beschikbare attributen zijn: namegeeft de contextnaam aan. Regels zullen deze naam gebruiken om de context te specificeren om om te schakelen als de regel overeenkomt.attribuutidentificeert de te gebruiken stijl voor een teken wanneer geen regel overeenkomt of wanneer een regel geen attribuut specificeert. In het laatste geval zal het attribuut van de context gespecificeerd in de context van de regel worden gebruikt.lineEndContextdefinieert de context waarnaar het systeem voor accentuering omschakelt als het einde van een regel wordt bereikt. Dit kan of de naam van een andere context zijn,#stayom de context niet om te schakelen (bijv.. niets doen) of#popwat de oorzaak is van het verlaten van deze context. Het is mogelijk om bijvoorbeeld#pop#pop#popte gebruiken om drie keer te poppen of zelfs#pop#pop!AndereContextom twee keer te poppen en om te schakelen naar de context genaamdAndereContext. Het is ook mogelijk om om te schakelen naar een context die behoort bij een andere taaldefinitie, op dezelfde manier als in de regelsIncludeRules, bijv.SomeContext##JavaScript. Omschakelen van context wordt ook beschreven in de paragraaf met de naam “Detectieregels accentueren”. Standaard: #stay.lineEmptyContextdefinieert de context als een lege regel wordt bereikt. De nomenclatuur van omschakelen van context is hetzelfde als eerder beschreven in lineEndContext. Standaard: #stay.fallthroughContextspecificeert de volgende context waarnaar om te schakelen als er geen regel overeenkomt. De nomenclatuur van context omschakelen is hetzelfde als eerder beschreven in lineEndContext. Standaard: #stay.fallthroughdefinieert of het accentueringssysteem naar de context schakelt gespecificeerd infallthroughContextals geen regel overeenkomt. Merk op dat sinds KDE Frameworks™ 5.62 dit attribuut is afgekeurd met voorkeur voorfallthroughContext, omdat als het attribuutfallthroughContextaanwezig is het impliciet wordt verstaan dat de waarde vanfallthroughtrue is. Standaard: false.noIndentationBasedFoldingschakelt op inspringen gebaseerd invouwen in de context uit. Als dit invouwen niet is geactiveerd, is dit attribuut nutteloos. Dit is gedefinieerd in het element folding van de groep general. Standaard: false.- Het element
itemDatais in de groepitemDatas. Het definieert de lettertypestijl en kleuren. Het is dus mogelijk om uw eigen stijlen en kleuren te definiëren. Wij bevelen echter aan om, indien mogelijk, bij de standaard stijlen te blijven zodat de gebruiker altijd dezelfde zal zien in verschillende talen. Soms is er echter geen andere manier en is het noodzakelijk de kleur- en lettertypeattributen te wijzigen. De attributen naam en defStyleNum zijn vereist, de anderen zijn optioneel. Beschikbare attributen zijn: namestelt de naam van het itemData in. Contexten en regels zullen deze naam in hun attribuut attribute gebruiken om naar een itemData te verwijzen.defStyleNumdefinieert welke standaard stijl te gebruiken. Beschikbare standaard stijlen worden later in detail verklaard.colordefinieert een kleur. Geldige formaten zijn '#rrggbb' of '#rgb'.selColordefinieert de selectiekleur.italicindien true, de tekst zal cursief worden.boldindien true, de tekst zal vet worden.underlineindien true, de tekst zal onderstreept worden.strikeOutindien true, door de tekst zal een streep worden gezet.spellCheckingindien true, de tekst zal gecontroleerd worden op spelling.- Het element
keywordsin de groepgeneraldefinieert sleutelwoordeigenschappen. Beschikbare attributen zijn: casesensitivemag true of false zijn. Indien true, worden alle sleutelwoorden met onderscheid tussen hoofd- en kleine letters met elkaar vergelekenweakDeliminatoris een lijst met tekens die niet als scheiding tussen woorden werken. Bijvoorbeeld: de punt'.'is een scheider van woorden. Als een sleutelwoord in eenlisteen punt bevat, dan zal die alleen overeenkomen als u de punt als een zwak scheidingsteken specificeert.additionalDeliminatordefinieert extra scheidingstekens.wordWrapDeliminatordefinieert tekens waarna een regel mag afbreken.Standaard scheidingstekens en regelafbreektekens zijn de tekens
.():!+,-<=>%&*/;?[]^{|}~\, spatie (' ') en tab ('\t').- Het element
commentin de groepcommentsdefinieert eigenschappen van commentaar die gebruikt worden voor → , → . Beschikbare attributen zijn: nameis ofwel singleLine of multiLine. Als u multiLine kiest zijn de attributen end en region vereist.startdefinieert de gebruikte tekenreeks om commentaar te laten beginnen. In C++ zou dit "/*" zijn. Dit attribute is vereist voor de typen multiLine en singleLine.enddefinieert de gebruikte tekenreeks om commentaar te laten eindigen. In C++ zou dit "*/" zijn. Alleen dit attribuut is beschikbaar en is vereist voor commentaar van het type multiLine.regionmoet de naam van het opvouwbare multiregel commentaar. U hebt beginRegion="Comment" ... endRegion="Comment" in uw regels, u zou region="Comment" moeten gebruiken. Op deze manier werkt verwijderen zelfs als u niet alle tekst van het multiregel commentaar selecteert. De cursor hoeft alleen in het multiregel commentaar te staan. Dit attribuut is alleen beschikbaar voor het type multiLine.positiedefinieert waar het commentaar op een enkele regel wordt ingevoegd. Standaard wordt het commentaar op een enkele regel geplaatst aan het begin van de regel op kolom 0, maar als u position="afterwhitespace" gebruikt wordt het commentaar ingevoegd rechts na voorloopwitruimte, voor het eerste niet-witruimteteken. Dit is nuttig om commentaar juist in te voegen in talen waar inspringen belangrijk is, zoals Python of YAML. Dit attribuut is optioneel en de enig mogelijke waarde is afterwhitespace.- Het element
foldingin de groepgeneraldefinieert de eigenschappen van het invouwen van broncode. Beschikbare attributen zijn: De markeringen voor code opvouwen, als
indentationsensitivetrue is, zullen worden toegevoegd gebaseerd op inspringen, zoals in de scripttaal Python. Het is gewoonlijk niet nodig dit in te stellen omdat de standaard false is.- Het element
emptyLinein de groepemptyLinesdefinieert welke regels beschouwd moeten worden als lege regels. Dit biedt het wijzigen van het gedrag van het attribuut lineEmptyContext in de elementencontext. Beschikbare attributen zijn: regexprdefinieert een reguliere expressie die behandeld zal worden als een lege regel. Standaard bevatten lege regels geen enkel teken, daarom voegt dit extra lege regels toe, als u, bijvoorbeeld, regels met spaties ook wil beschouwen als lege regels. In de meeste syntaxisdefinities is er geen noodzaak om dit attribuut in te zetten.- Het element
encodingin de groepspellcheckingdefinieert een codering van tekens voor spellingcontrole. Beschikbare attributen: charis een gecodeerd teken.stringis een serie tekens die gecodeerd zullen worden als het teken char in de spellingcontrole. In de taal LaTeX, bijvoorbeeld, representeert de tekenreeks\"{A}het tekenÄ.
Standaard stijlen zijn al verklaard, als een korte samenvatting: Standaard stijlen zijn voorgedefinieerde lettertypen- en kleurstijlen.
- Algemene standaard stijlen:
dsNormal, wanneer geen speciale accentuering is vereist.dsKeyword, ingebouwde sleutelwoorden van taal.dsFunction, functie-aanroepen en definities.dsVariable, indien van toepassing: namen van variabelen (bijv. $eenVar in PHP/Perl).dsControlFlow, sleutelwoorden voor flowcontrol zoals if, else, switch, break, return, yield, ...dsOperator, operatoren zoals + - * / :: < >dsFunction, ingebouwde functies, klassen en objecten.dsExtension, gezamenlijke extensies, zoals Qt™-klassen en functies/macro's in C++ en Python.dsPreprocessor, preprocessor statements of macro-definities.dsAttribute, annotaties zoals @override en __declspec(...).- Standaard stijlen gerelateerd aan tekenreeksen
dsChar, enkele tekens, zoals 'x'.dsSpecialChar, tekens met een speciale betekenis in tekenreeksen zoals escapes, substituties of regex-operatoren.dsString, tekenreeksen zoals "hello world".dsVerbatimString, letterlijke of raw-tekenreeksen zoals 'raw \backlash' in Perl, CoffeeScript en shells, evenals r'\raw' in Python.dsSpecialString, SQL, regexes, HERE-docs, LATEX math mode, ...dsImport, import, include, require van modulen.- Standaard stijlen gerelateerd aan getallen:
dsDataType, ingebouwde typen gegevens zoals int, void, u64.dsDecVal, decimale waarden.dsBaseN, waarden met een andere basis dan 10.dsFloat, drijvende-komma waarden.dsConstant, ingebouwde en gebruikergedefineerde constanten zoals pi.- Standaard stijlen gerelateerd aan commentaar en documentatie:
dsComment, commentaar.dsDocumentation, /** Documentatie commentaar */ of """docstrings""".dsAnnotation, documentatiecommando's zoals @param, @brief.dsCommentVar, de in bovenstaande commando's gebruikte namen van variabelen, zoals "foobar" in @param foobar.dsRegionMarker, gebiedsmarkeringen zoals//BEGIN, //END in commentaar.- Andere standaard stijlen:
dsInformation, notities en tips zoals @note in doxygen.dsWarning, waarschuwingen zoals @warning in doxygen.dsAlert, speciale woorden zoals TODO, FIXME, XXXX.dsError, accentuering van fouten en foute syntaxis.dsOthers, wanneer niets anders past.
Deze paragraaf beschrijft de syntaxis van detectieregels.
Elke regel kan nul of meer tekens aan het begin van de tekenreeks bevatten, waartegen ze worden getest. Als de regel overeenkomt worden de overeenkomstige tekens toegekend aan de stijl of attribuut gedefinieerd door de regel en een regel kan vragen de huidige context om te schakelen.
Een regel ziet er als volgt uit:
<RuleName attribute="(identifier)" context="(identifier)" [regelspecifieke attributen] />
Het attribute identificeert de te gebruiken stijl voor overeenkomende tekens bij naam en de context identificeert de vanaf hier te gebruiken context.
De context kan worden geïdentificeerd door:
Een identifier, wat de naam is van de andere context.
Een opdracht die de engine vertelt om in de huidige context te blijven (
#stay) of terug te gaan naar een eerdere context met in de tekenreeks (#pop). Een lege of afwezige context is gelijk aan#stay.Om meer stappen terug te gaan kan het #pop commando worden herhaald:
#pop#pop#popEen order gevolgd door een uitroepteken (!) en een identifier, die er voor zorgt dat de engine eerst de order volgt en dan omschakelt naar de andere context, bijv.
#pop#pop!AndereContext.Een identifier, die een contextnaam is, gevolgd door twee hashes (
##) en een andere identifier, die de naam is van een taaldefinitie. Deze naamgeving is gelijk aan die gebruikt inIncludeRulesregels en u toestaat om naar een context om te schakelen behorende bij een andere syntaxisaccentueringsdefinitie, bijv.SomeContext##JavaScript.
Specifieke attributen van regels variëren en zijn beschreven in de volgende secties.
Gezamenlijke attributen
Alle regels hebben de volgende gezamenlijke attributen en zijn beschikbaar wanneer (common attributes) verschijnt. Alle attributen zijn optioneel.
attribute: Een attribuut komt overeen met een gedefinieerd itemData. Standaard: attribuut uit de context gespecificeerd in attribuut context.
context: Specificeer de context waarnaar het accentueringssysteem omschakelt als de regel overeenkomt. Standaard: #stay.
beginRegion: Start een invouwblok voor code. Standaard: niet ingesteld.
endRegion: Sluit een invouwblok voor code. Standaard: niet ingesteld.
lookAhead: Indien true, zal het accentueringssysteem niet de overeenkomende lengte verwerken. Standaard: false.
firstNonSpace: Komt alleen overeen als de tekenreeks de eerste niet-witruimte in de regel. Standaard: false.
column: Komt alleen overeen als de kolom overeenkomt. Standaard: niet ingesteld.
Dynamische regels
Sommige regels staan het optionele attribuut dynamic toe van het type boolean dat standaard de waarde false heeft. Als dynamic true is kan een regel plaatshouders bevatten die de tekst representeren die overeenkomt met een reguliere expressie die schakelt naar de huidige context in zijn attributen tekenreeks of teken. In een tekenreekswordt de plaatshouder %N (waar N een getal is) vervangen door de overeenkomstige vangst N uit de aanroepende reguliere expressie, beginnend bij 1. In een teken moet de plaatshouder een getal N zijn en het zal worden vervangen door het eerste teken van de overeenkomstige vangst N uit de aanroepende reguliere expressie. Wanneer een regel dit attribuut toestaat zal het een (dynamic) bevatten.
dynamic: kan (true|false) zijn.
Hoe werkt het:
In de reguliere expressies van de regels RegExpr wordt alle tekst binnen haakjes (PATTERN) gevangen en onthouden. Deze vangsten kunnen gebruikt worden in de context waarin het is gevangen, in de regels met het attribuut dynamic true, door %N (in String) of N (in char).
Het is belangrijk om te noemen dat een tekst gevangen in een RegExpr regel alleen wordt opgeslagen voor in deze context, gespecificeerd in zijn context-attribuut.
Tip
Als de vangsten niet gebruikt zullen worden, zowel door dynamische regels als in dezelfde reguliere expressie, dan zullen
non-capturing groeperingenmoeten worden gebruikt:(?:PATTERN)De lookahead or lookbehind groeperingen zoals
(?=PATROON),(?!PATROON)of(?<PATROON)worden niet gevangen. Zie voor meer informatie Reguliere expressies.De gevangen groeperingen kunnen gebruikt worden binnen dezelfde reguliere expressie, met gebruik van respectievelijk
\Nin plaats van%N. Voor meer informatie, zie Vangen van overeenkomende tekst (achterwaartse referenties) in Reguliere expressies.
Voorbeeld 1:
In dit eenvoudige voorbeeld wordt de tekst overeenkomend met de reguliere expressie =* gevangen en ingevoegd in %1 in de dynamische regel. Dit biedt het commentaar om te eindigen met dezelfde hoeveelheid van = als aan het begin. Dit komt overeen met tekst als: [[ commentaar ]], [=[ commentaar ]=] of [=====[ commentaar ]=====].
Bovendien zijn de vangsten alleen beschikbaar in deze context Multi-line commentaar.
<context name="Normaal" attribute="Normal Text" lineEndContext="#stay"> <RegExpr context="Multi-line Comment" attribute="Comment" String="\[(=*)\[" beginRegion="RegionComment"/> </context> <context name="Multi-line Comment" attribute="Comment" lineEndContext="#stay"> <StringDetect context="#pop" attribute="Comment" String="]%1]" dynamic="true" endRegion="RegionComment"/> </context>
Voorbeeld 2:
In de dynamische regel komt %1 overeen met de vangst die overeenkomt met #+ en %2 met "+. Dit komt overeen met tekst als: #label""""inside the context""""#.
Deze vangsten zullen niet beschikbaar zijn in andere contexten, zoals OtherContext, FindEscapes of SomeContext.
<context name="SomeContext" attribute="Normal Text" lineEndContext="#stay"> <RegExpr context="#pop!NamedString" attribute="String" String="(#+)(?:[\w-]|[^[:ascii:]])("+)"/> </context> <context name="NamedString" attribute="String" lineEndContext="#stay"> <RegExpr context="#pop!OtherContext" attribute="String" String="%2(?:%1)?" dynamic="true"/> <DetectChar context="FindEscapes" attribute="Escape" char="\"/> </context>
Voorbeeld 3:
Dit komt overeen met tekst zoals: Class::function<T>( ... ).
<context name="Normal" attribute="Normal Text" lineEndContext="#stay">
<RegExpr context="FunctionName" lookAhead="true"
String="\b([a-zA-Z_][\w-]*)(::)([a-zA-Z_][\w-]*)(?:<[\w\-\s]*>)?(\()"/>
</context>
<context name="FunctionName" attribute="Normal Text" lineEndContext="#pop">
<StringDetect context="#stay" attribute="Class" String="%1" dynamic="true"/>
<StringDetect context="#stay" attribute="Operator" String="%2" dynamic="true"/>
<StringDetect context="#stay" attribute="Function" String="%3" dynamic="true"/>
<DetectChar context="#pop" attribute="Normal Text" char="4" dynamic="true"/>
</context>
Lokale scheidingstekens
Sommige regels bieden de optionele attributen weakDeliminator en additionalDeliminator die zijn gecombineerd met attributen met dezelfde tagnaamsleutelwoorden. Wanneer bijvoorbeeld '%' een zwak scheidingstekens van sleutelwoorden is, kan het alleen voor een regel een woordscheidingsteken worden door het in zijn attribuut additionalDeliminator te zetten. Wanneer een regel deze attributen biedt zal het een (lokale scheidingstekens) bevatten.
weakDeliminator: lijst met tekens die niet werken als woordscheidingstekens.
additionalDeliminator definieert extra scheidingstekens.
- DetectChar
Detecteert een enkele specifiek teken. Gewoonlijk gebruikt, bijvoorbeeld om het einde van een tekenreeks tussen accenten of aanhalingstekens.
<DetectChar char="(teken)" (common attributes) (dynamic) />
Het attribuut
chardefinieert het teken dat moet overeenkomen.- Detect2Chars
Detecteert twee specifieke tekens in een gedefinieerde volgorde.
<Detect2Chars char="(teken)" char1="(teken)" (gezamenlijke attributen) />
Het attribuut
chardefinieert het eerste teken dat moet overeenkomen,char1the tweede.Deze regel is aanwezig voor historische redenen en voor leesbaarheid heeft het voorkeur om
StringDetectte gebruiken.- AnyChar
Detecteer één teken van een set van gespecificeerde tekens.
<AnyChar String="(tekenreeks)" (common attributes) />
Het attribuut
Stringdefinieert de set tekens.- StringDetect
Detecteert een exacte tekenreeks.
<StringDetect String="(tekenreeks)" [insensitive="true|false"] (common attributes) (dynamic) />
Het attribuut
Stringdefinieert de overeen te komen tekenreeks. Het attribuutinsensitiveis standaard false en wordt doorgegeven aan de vergelijkingsfunctie van de tekenreeks. Als de waarde true is wordt 'insensitive' vergelijking gebruikt.- WordDetect
Detecteert een exacte tekenreeks maar vereist extra woordgrenzen zoals een punt
'.'of witruimte aan het begin en eind van het woord. Denk aan\b<tekenreeks>\bin termen van een reguliere expressie, het is echter sneller dan de regelRegExpr.<WordDetect String="(tekenreeks)" [insensitive="true|false"] (gezamenlijke attributen) (lokale scheidingstekens) />
Het attribuut
Stringdefinieert de overeen te komen tekenreeks. Het attribuutinsensitiveis standaard false en wordt doorgegeven aan de vergelijkingsfunctie van de tekenreeks. Als de waarde true is wordt 'insensitive' vergelijking gebruikt.Sinds: Kate 3.5 (KDE 4.5)
- RegExpr
Komt overeen met een reguliere expressie.
<RegExpr String="(tekenreeks)" [insensitive="true|false"] [minimal="true|false"] (common attributes) (dynamic) />
Het attribuut
Stringdefinieert de reguliere expressie.insensitiveis standaard false en wordt doorgegeven aan de engine voor de reguliere expressie.minimalis standaard false en wordt doorgegeven aan de engine voor de reguliere expressie.Omdat de regels altijd vergeleken worden met het begin van de huidige tekenreeks, zal een reguliere expressie die begint met een dakje (
^) aangeven dat de regel alleen overeen moet komen met het begin van een regel.Zie Reguliere expressies voor meer informatie hierover.
- trefwoord
Detecteert een sleutelwoord uit een gespecificeerde lijst.
<keyword String="(lijstnaam)" (common attributes) (lokale scheidingstekens) />
Het attribuut
Stringidentificeert de lijst met sleutelwoorden met een naam. Een lijst met die naam moet bestaan.Het systeem voor accentuering bewerkt sleutelwoordregels op een zeer geoptimaliseerde manier. Dit maakt het absoluut noodzakelijk dat elk te vinden sleutelwoord omgeven wordt door gedefinieerde scheidingstekens, ofwel impliciet (de standaard scheidingstekens) of expliciet gespecificeerd binnen de eigenschap additionalDeliminator van de sleutelwoord-tag.
Als een te vinden sleutelwoord een scheidingsteken moet bevatten, dan moet dit teken toegevoegd worden aan de eigenschap weakDeliminator van de sleutelwoord-tag. Dit teken zal dan zijn eigenschap scheidingsteken in alle sleutelwoord-regels verliezen. Het is ook mogelijk om het attribuut weakDeliminator van sleutelwoord te gebruiken zo dat deze wijziging alleen op deze regel van toepassing is.
- Int
Een geheel getal detecteren (als de reguliere expressie
\b[0-9]+).<Int (gezamenlijke attributen) (lokale scheidingstekens) />
Deze regel heeft geen specifieke attributen.
- Zwevend
Een drijvende kommagetal detecteren( als de reguliere expressie:
(\b[0-9]+\.[0-9]*|\.[0-9]+)([eE][-+]?[0-9]+)?).<Drijvende komma (gezamenlijke attributen) (lokale scheidingstekens) />
Deze regel heeft geen specifieke attributen.
- HlCOct
Een octale representatie van een getal detecteren (als de reguliere expressie:
\b0[0-7]+).<HlCOct (gezamenlijke attributen) (lokale scheidingstekens) />
Deze regel heeft geen specifieke attributen.
- HlCHex
Een hexadecimale representatie van een hexadecimaal getal (als de reguliere expressie:
\b0[xX][0-9a-fA-F]+).<HlCHex (gezamenlijke attributen) (lokale scheidingstekens) />
Deze regel heeft geen specifieke attributen.
- HlCStringChar
Detecteer een escaped teken.
<HlCStringChar (common attributes) />
Deze regel heeft geen specifieke attributen.
Komt overeen met de letterlijke representatie van tekens, gewoonlijk gebruikt in programmacode, bijvoorbeeld
\n(nieuwe-regel) of\t(TAB).De volgende tekens zullen overeenkomen als ze volgen op een backslash (
\):abefnrtv"'?\. Bovendien escaped hexadecimale getallen zoals bijvoorbeeld\xffen escaped octale getallen, zoals bijvoorbeeld\033zullen overeenkomen.- HlCChar
Detecteer een C-teken.
<HlCChar (gezamenlijke attributen) />
Deze regel heeft geen specifieke attributen.
Komt overeen met een C-teken tussen accenten (Bijvoorbeeld:
'c'). De accenten kunnen een eenvoudig teken zijn of een escaped teken. Zie HlCStringChar voor overeenkomende reeksen van escaped tekens.- RangeDetect
Detecteert een tekenreeks met gedefinieerde begin- en eindtekens.
<RangeDetect char="(teken)" char1="(teken)" (gezamenlijke attributen) />
chardefines the character starting the range,char1the character ending the range.Bruikbaar om bijvoorbeeld kleine tekenreeksen of zoiets te detecteren, maar merk op dat de accentiëringsengine werkt op één regel tegelijk, hierdoor zullen tekenreeksen over meerdere regels niet gevonden worden.
- LineContinue
Komt overeen met een gespecificeerd teken aan het eind van een regel.
<LineContinue (gezamenlijke attributen) [char="\"] />
charoptioneel teken dat moet overeenkomen, standaard is de backslash ('\'). Nieuw sinds KDE 4.13.Deze regel is bruikbaar voor het omschakelen van context aan het einde van een regel. Dit is bijvoorbeeld nodig in C/C++ om macro's of tekenreeksen door te laten lopen.
- IncludeRules
Voeg regels in uit een ander context- of taalbestand.
<IncludeRules context="contextlink" [includeAttrib="true|false"] />
Het attribuut
contextdefinieert welke context in te voegen.Als het een eenvoudige tekenreeks is dan zijn alle gedefinieerde regels in de huidige context ingevoegd, bijvoorbeeld:
<IncludeRules context="anotherContext" />
Als de tekenreeks
##bevat zal het accentueringssysteem zoeken naar een context uit een andere taaldefinitie met de gegeven naam, bijvoorbeeld<IncludeRules context="String##C++" />
zou de context String uit de accentueringsdefinitie van C++ invoegen.
Als attribuut
includeAttribtrue is, dan wijzigt het doelattribuut naar die van de bron. Dit is vereist om bijvoorbeeld het aanbrengen van commentaar te laten werken als tekst die overeenkomt met de ingevoegde context een verschillende accentuering is van de host-context.- DetectSpaces
Detecteert witruimte.
<DetectSpaces (gezamenlijke attributen) />
Deze regel heeft geen specifieke attributen.
Gebruik deze regel als u weet dat er verschillende witruimtes aankomen, bijvoorbeeld aan het begin van inspringende regels. Deze regel slaat alle witruimte in een keer over, in plaats van testen met meerdere regels en een voor een overslaan vanwege geen overeenkomst.
- DetectIdentifier
Tekenreeksen voor een identifier detecteren (als de reguliere expressie:
[a-zA-Z_][a-zA-Z0-9_]*).<DetectIdentifier (gezamenlijke attributen) />
Deze regel heeft geen specifieke attributen.
Gebruik deze regel om een reeks woordtekens in een keer over te slaan, in plaats van deze te testen met meerdere regels en ze een voor een over te slaan omdat er geen overeenkomst is.
Als u hebt begrepen hoe het omschakelen van context werkt zal het gemakkelijk zijn om definities voor accentuering te schrijven. Hoewel u zeer zorgvuldig moet controleren welke regel u kiest in welke situatie. Reguliere expressies zijn erg krachtig, maar ze zijn langzaam vergeleken met de andere regels. Dus zou u de volgende tips nog eens moeten bekijken.
Reguliere expressies zijn gemakkelijk te gebruiken maar vaak is er een andere veel snellere manier om hetzelfde resultaat te behalen. U wilt alleen een overeenkomst vinden met het teken
'#'als het het eerste teken is in de regel. Een oplossing gebaseerd op een reguliere expressie zou er zo uit zien:<RegExpr attribute="Macro" context="macro" String="^\s*#" />
. U kunt hetzelfde veel sneller bereiken door te gebruiken:
<DetectChar attribute="Macro" context="macro" char="#" firstNonSpace="true" />
. Als u de reguliere expressie
'^#'wilt laten vereen komen dan kunt u nog steedsDetectChargebruiken met het attribuutcolumn="0". Het attribuutcolumntelt tekens zodat een tab nog één teken is.Gebruik in regels
RegExprhet attribuutcolumn="0"als het patroon^PATROONgebruikt zal worden om met tekst overeen te komen aan het begin van een regel. Dit verbetert de prestaties, omdat het niet zal zoeken naar overeenkomsten in de rest van de kolommen.Gebruik in reguliere expressies non-capturing groeperingen
(?:PATROON)in plaats van vangstgroeperingen(PATROON), als de vangsten niet gebruikt zullen worden in dezelfde reguliere expressie of in dynamische regels. Dit vermijdt het onnodig opslaan van vangsten.U kunt van contexts wisselen zonder tekens te bewerken. Neem aan dat u van context wilt wisselen wanneer u de tekenreeks
*/tegenkomt, maar u moet die tekenreeks in de volgende context bewerken. De onderstaande regel zal overeenkomen en het attribuutlookAheadzal de overeenkomende tekenreeks voor accentuering bewaren voor de volgende context.<StringDetect attribute="Comment" context="#pop" String="*/" lookAhead="true" />
Gebruik
DetectSpacesals u weet dat er veel witruimtes zijn.Gebruik
DetectIdentifierin plaats van de reguliere expressie'[a-zA-Z_]\w*'.Gebruik standaard stijlen wanneer dat kan. Op deze manier vindt de gebruiker een bekende omgeving.
Kijk in andere XML-bestanden om te zien hoe andere mensen ingewikkelde regels implementeren.
U kunt elk XML-bestand valideren met de opdracht validatehl.sh mySyntax.xml. Het bestand
validatehl.shgebruiktlanguage.xsddie beiden beschikbaar zijn in Opslagruimte voor accentuering van syntaxis.Als u complexe reguliere expressies erg vaak gebruikt dan kunt u ENTITIES gebruiken. Voorbeeld:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE language [ <!ENTITY myref "[A-Za-z_:][\w.:_-]*"> ]>Nu kunt u &myref; gebruiken in plaats van de reguliere expressie.
In de bewerker Kate kunt u syntaxes herladen met de ingebouwde opdrachtregel (
F7standaard sneltoets) en de opdracht reload-highlighting.U kunt het hulpmiddel op de opdrachtregel genaamd
ksyntaxhighlighter6gebruiken (kate-syntax-highlighterop oudere versies) om een syntaxis te testen en de stijl en gebieden geassocieerd met elk deel van een tekst te tonen.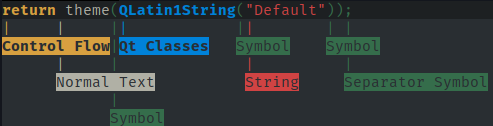
Resultaat van ksyntaxhighlighter6 --output-format=ansi --syntax-trace=format test.cpp.
Gebruik ksyntaxhighlighter6 -h voor meer opties.