El ressaltat de la sintaxi és el que fa que l'editor mostri automàticament text en diferents estils/colors, depenent de la funció de la cadena en relació amb la finalitat del fitxer. En el codi font d'un programa, per exemple, les sentències de control es poden presentar en negreta, mentre que els tipus de dades i els comentaris poden tenir diferents colors que la resta del text. Això millora considerablement la llegibilitat del text, i ajuda l'autor a ser més eficient i productiu.

Una funció de C++, presentada amb ressaltat de la sintaxi.

La mateixa funció de C++, sense ressaltat.
Dels dos exemples, quin resulta més fàcil de llegir?
La KatePart compta amb un sistema de ressaltat de sintaxi flexible, configurable i capaç, la distribució estàndard proveeix definicions per a una gran varietat de llenguatges de programació, creació de scripts i de marques. A més podeu proveir les vostres pròpies definicions en simples fitxers XML.
La KatePart detectarà automàticament les regles de la sintaxi correctes quan obriu un fitxer, basant-se en el tipus MIME del fitxer, determinat per la seva extensió, o, si no en té, pel seu contingut. Si l'elecció no és la correcta, podreu establir-la manualment des del menú → .
Els estils i colors emprats per a cada definició de ressaltat de sintaxi es poden configurar utilitzant la pestanya Estils del text ressaltat del Diàleg de configuració, mentre que els tipus MIME i extensions de fitxer per als que s'hauran d'utilitzar, es poden gestionar utilitzant la pàgina Modes i tipus de fitxer.
Nota
El ressaltat de la sintaxi té el seu ús en la millora de la llegibilitat del text, però no podeu confiar-hi per a validar que el text és correcte. Marcar el text en funció de la seva sintaxi pot ser difícil, depenent del format que s'estigui emprant, i en alguns casos els autors de les regles de la sintaxi poden estar orgullosos si es processa correctament el 98% del text, si bé caldrà un estil molt rar per a veure el 2% incorrecte.
Aquesta secció tractarà sobre el mecanisme de ressaltat de la sintaxi de la KatePart amb més detall. Recomanem la seva lectura si voleu aprendre sobre seu, o si voleu crear o canviar les definicions de la sintaxi.
Sempre que obriu un fitxer, una de les primeres coses que fa l'editor de la KatePart és detectar quina definició de la sintaxi s'emprarà per al fitxer. Mentre va llegint el text del fitxer, i mentre hi va escrivint, el sistema de ressaltat de la sintaxi analitza el text utilitzant les regles establertes per la definició de la sintaxi i marcant a on comencen i acaben els diferents contexts i estils.
Quan escriviu en el document, el text nou és analitzat i marcat al vol, de manera que si suprimiu un caràcter que marca el començament o el final d'un context, l'estil del text adjacent canviarà en conseqüència.
Les definicions de la sintaxi utilitzades per al sistema de ressaltat de la sintaxi de la KatePart són fitxers XML, que contenen
Regles per a detectar el paper del text, organitzades en blocs segons el context
Llistes de paraules clau
Definicions dels elements d'estil
Quan s'analitza el text, les regles de detecció són avaluades en l'ordre en el qual estan definides, i si el començament de la cadena actual coincideix amb la regla, s'utilitzarà el context relacionat. El punt d'inici del text es mou al punt final en el qual la regla coincideix i comença un nou cicle de regles, començant en el context establert per la regla coincident.
Les regles de la detecció són el nucli del sistema de detecció del ressaltat. Una regla és una cadena, un caràcter o una expressió regular contra què haurà de coincidir el text que s'està analitzant. Conté informació sobre l'estil a emprar per a la part coincident del text. Es pot canviar el context de treball del sistema, ja sigui cap a un context mencionat explícitament o cap a l'anterior context emprat pel text.
Les regles s'organitzen en grups de context. Un grup de context s'utilitza per als conceptes del text principal dins del format, per exemple, les cadenes de text entre cometes o els blocs de comentaris en el codi font d'un programa. Això garanteix que el sistema de ressaltat no necessita realitzar un cicle per a totes les regles quan no és necessari, i que algunes seqüències de caràcters del text es poden tractar de forma diferent depenent del context actual.
En les regles és possible generar contexts dinàmicament per a permetre l'ús de dades específiques d'una instància.
En alguns llenguatges de programació, els nombres enters són tractats pel compilador (el programa que converteix el codi font en un executable binari) d'una forma diferent dels de coma flotant, i poden haver-hi caràcters que tinguin un significat especial dins d'una cadena entre cometes. En aquests casos, té sentit processar-los de diferent manera que el text adjacent, perquè resultin fàcils d'identificar. De manera que si no representen contexts especials, poden ser vistos com a tals pel sistema de ressaltat de la sintaxi, així que són marcats per a un processat diferent.
Una definició de la sintaxi pot contenir tants estils com siguin requerits per a cobrir tots els conceptes del format per què s'utilitza.
En molts formats hi ha llistes de paraules que representen un concepte específic. Per exemple, en els llenguatges de programació, les sentències de control són un concepte, els noms de tipus de dades un altre, i les funcions integrades en el llenguatge són un tercer. El sistema de ressaltat de la sintaxi de la KatePart pot utilitzar aquestes llistes per a detectar i marcar paraules en el text per a emfatitzar conceptes dels formats del text.
Si obriu un fitxer de codi font en C++, un fitxer de codi font en Java™ i un document en HTML a la KatePart, podreu comprovar que tot i que els formats són diferents i, per tant, les paraules que reben un tractament especial també són diferents, els colors emprats són els mateixos. Això és perquè la KatePart té una llista predefinida d'estils predeterminats, els quals s'empren en les definicions individuals de la sintaxi.
Això facilita reconèixer conceptes similars en diferents formats de text. Per exemple, els comentaris estan presents en pràcticament qualsevol llenguatge de programació, creació de scripts o de marques, i si es presenten utilitzant el mateix estil en tots els llenguatges, no haureu de parar-vos a pensar i identificar la seva posició en el text.
Suggeriment
Tots els estils de definició de la sintaxi utilitzen un dels estils predeterminats. Hi ha poques definicions de la sintaxi que utilitzin més estils dels que hi ha de manera predeterminada, així que, si empreu un format molt sovint, potser val la pena obrir el diàleg de configuració per a veure si alguns conceptes estan emprant el mateix estil. Per exemple, tan sols hi ha un estil predeterminat per a les cadenes, però com el llenguatge de programació Perl utilitza dos tipus de cadena, podeu millorar el ressaltat configurant ambdues de forma lleugerament diferent. Més endavant s'explicaran tots els estils predeterminats disponibles.
El KatePart utilitza l'entorn de treball per al ressaltat de la sintaxi dels Frameworks del KDE™. Els fitxers en XML predeterminats del ressaltat distribuïts amb el KatePart són compilats dintre de la biblioteca de ressaltat de la sintaxi.
Aquesta secció és una introducció al format XML per a la definició del ressaltat. Descriu els components principals, el seu significat i utilització. La següent secció entra en detalls amb les regles de la detecció.
La definició formal, també coneguda com la XSD es troba al repositori del ressaltat de la sintaxi al fitxer language.xsd
Els fitxers .xml personalitzats per a la definició del ressaltat es troben a org.kde.syntax-highlighting/syntax/ a la carpeta d'usuari que trobareu amb qtpaths que normalment és --paths GenericDataLocation$HOME/.local/share//usr/share/.
En els paquets Flatpak i Snap, la carpeta anterior no funcionarà, ja que la ubicació de les dades és diferent per a cada aplicació. En una aplicació de Flatpak, la ubicació dels fitxers XML generalment és $HOME/.var/app/nom_paquet_flatpak/data/org.kde.syntax-highlighting/syntax/$HOME/snap/nom_paquet_snap/current/.local/share/org.kde.syntax-highlighting/syntax/
Al Windows® aquests fitxers es troben a %USERPROFILE%\AppData\Local\org.kde.syntax-highlighting\syntax. %USERPROFILE% que generalment s'expandeix a C:\Users\.usuari
En resum, per a la majoria de les configuracions, la carpeta dels fitxers XML personalitzats és la següent:
| Per a l'usuari local | |
| Per a tots els usuaris | /usr/share/org.kde.syntax-highlighting/syntax/ |
| Per als paquets Flatpak | |
| Per als paquets Snap | |
| Al Windows® | %USERPROFILE%\AppData\Local\org.kde.syntax-highlighting\syntax |
| Al macOS® | |
Si hi ha múltiples fitxers per al mateix llenguatge, es carregarà el fitxer amb l'atribut version més alt en l'element language.
Principals seccions dels fitxers de definició del ressaltat de la KatePart
- Tots els fitxers de ressaltat contenen una capçalera que estableix la versió XML:
<?xml version="1.0" encoding="UTF-8"?>
- La part principal del fitxer de la definició és l'element
language. Els atributs disponibles són: Atributs requerits:
nameestableix el nom del llenguatge. Després apareixerà als menús i als diàlegs.sectionespecifica la categoria.extensionsdefineix les extensions dels fitxers, com "*.cpp;*.h"versionespecifica la versió actual del fitxer de definició en termes d'un nombre enter. Sempre que es canvia un fitxer de definició del ressaltat, assegureu-vos d'augmentar aquest número.kateversionespecifica l'última versió implementada de la KatePart.Atributs opcionals:
mimetypefitxers associats amb el tipus MIME.casesensitivedefineix quan les paraules clau distingeixen o no les majúscules i minúscules.priorityés necessària si una altra definició de ressaltat utilitza les mateixes extensions. S'emprarà la de major prioritat.authorconté el nom de l'autor i la seva adreça de correu electrònic.licenseconté la llicència, normalment la llicència del MIT per a fitxers nous de ressaltat de la sintaxi.styleconté el llenguatge proporcionat i és utilitzat pels sagnadors per a l'atributrequired-syntax-style.indenterdefineix quin sagnat emprar de manera predeterminada. Els atributs disponibles són: ada, normal, cstyle, cmake, haskell, latex, lilypond, lisp, lua, pascal, python, replicode, ruby i xml.hiddendefineix quan hauria d'aparèixer el nom en els menús de la KatePart.De manera que la línia següent pot tenir un aspecte similar a:
<language name="C++" version="1" kateversion="2.4" section="Sources" extensions="*.cpp;*.h" />
- A continuació estaria l'element
highlighting, el qual conté l'element opcionallisti els elements requeritscontextsiitemDatas. Els elements
listcontenen una llista de paraules clau. En aquest cas les paraules clau són class i const. Podeu afegir tantes llistes com us calguin.Des del Frameworks del KDE™ 5.53, una llista pot incloure paraules clau d'una altra llista o llenguatge/fitxer, utilitzant l'element
include. Els caràcters##s'utilitzen per a separar el nom de la llista i el nom de la definició del llenguatge, de la mateixa manera que a la reglaIncludeRules. Això és útil per a evitar la duplicació de llistes de paraules clau, si necessiteu incloure les paraules clau d'un altre llenguatge/fitxer. Per exemple, la llista altre_nom conté la paraula clau str i totes les paraules clau de la llista types, la qual pertany al llenguatge C++ de l'ISO.L'element
contextsconté tots els contexts. El primer és l'emprat de manera predeterminada i amb aquest s'iniciarà el ressaltat. Hi ha dues regles en el context text_normal, el qual farà coincidir la llista de paraules clau amb el nom algun_nom i una regla que detecta una cometa i canvia el context a cadena. Per a aprendre més sobre les regles llegiu el següent capítol.La tercera part és l'element
itemDatas. Conté tots els colors i estils de lletra que necessiten els contexts i les regles. En aquest exemple, s'utilitzenitemDatatext_normal, cadena i paraula_clau.<highlighting> <list name="algun_nom"> <item>class</item> <item>const</item> </list> <list name="altre_nom"> <item>str</item> <include>types##ISO C++</include> </list> <contexts> <context attribute="text_normal" lineEndContext="#pop" name="text_normal" > <keyword attribute="paraula_clau" context="#stay" String="algun_nom" /> <keyword attribute="paraula_clau" context="#stay" String="altre_nom" /> <DetectChar attribute="cadena" context="cadena" char=""" /> </context> <context attribute="cadena" lineEndContext="#stay" name="cadena" > <DetectChar attribute="cadena" context="#pop" char=""" /> </context> </contexts> <itemDatas> <itemData name="text_normal" defStyleNum="dsNormal" /> <itemData name="paraula_clau" defStyleNum="dsKeyword" /> <itemData name="cadena" defStyleNum="dsString" /> </itemDatas> </highlighting>- L'última part de la definició del ressaltat és la secció opcional
general. Pot contenir informació sobre paraules clau, plegat del codi, comentaris, sagnat, línies buides i verificació de l'ortografia. La secció
commentdefineix amb quina cadena s'introdueix un comentari en una línia senzilla. També podeu definir un comentari en múltiples línies utilitzant multiLine amb l'atribut addicional end. Això s'empra si l'usuari prem la drecera corresponent per a comenta/descomenta.La secció
keywordsdefineix si les llistes de paraules clau distingeixen les majúscules i minúscules o no. Més endavant s'explicaran altres atributs.Les altres seccions,
folding,emptyLinesispellchecking, normalment no són necessàries i s'expliquen més endavant.<general> <comments> <comment name="singleLine" start="#"/> <comment name="multiLine" start="###" end="###" region="CommentFolding"/> </comments> <keywords casesensitive="1"/> <folding indentationsensitive="0"/> <emptyLines> <emptyLine regexpr="\s+"/> <emptyLine regexpr="\s*#.*"/> </emptyLines> <spellchecking> <encoding char="á" string="\'a"/> <encoding char="à" string="\`a"/> </spellchecking> </general> </language>
Aquesta part descriu tots els atributs disponibles per als contexts, llistes de dades, paraules clau, comentaris, plegat del codi i sagnat.
- L'element
contextpertany al grupcontexts. Un context defineix les regles específiques de context que s'han de seguir quan el sistema de ressaltat abasta el final d'una línia. Els atributs disponibles són: nameestableix el nom del context. Les regles utilitzaran el nom per a especificar el context al qual canviar si les regles coincideixen.attributeidentifica l'estil a utilitzar per a un caràcter quan no coincideix cap regla o quan una regla no especifica cap atribut. En aquest últim cas, s'utilitzarà attribute del context especificat a la regla context.lineEndContextdefineix el context al qual canviarà el sistema de ressaltat si abasta el final de la línia. Pot ser un nom o un altre context,#staypermetrà que no es canviï el context (p. ex., no fer res) o#popfarà que deixi aquest context. És possible utilitzar, per exemple#pop#pop#popper a sortir tres vegades, o fins i tot#pop#pop!AltreContextperquè aparegui dues vegades i canviar a un context anomenatAltreContext. També és possible canviar a un context que pertanyi a una altra definició de llenguatge, de la mateixa manera que en les reglesIncludeRules, p. ex.,AlgunContext##JavaScript. Els canvis de context també es descriuen a «Regles de detecció del ressaltat». De manera predeterminada: #stay.lineEmptyContextdefineix el context si es troba una línia buida. La nomenclatura dels commutadors de context és la mateixa que s'ha descrit anteriorment a lineEndContext. De manera predeterminada: #stay.fallthroughContextespecifica el context següent al qual canviar si no coincideix cap regla. La nomenclatura dels commutadors de context és la mateixa que s'ha descrit anteriorment a lineEndContext. De manera predeterminada: #stay.fallthroughdefineix si el sistema de ressaltat canviarà al context especificat afallthroughContextsi no coincideix cap regla. Cal tenir en compte que, des dels Frameworks™ 5.62 del KDE, aquest atribut està en desús a favor defallthroughContext, ja que si està present aquest atribut, s'entendrà implícitament que el valor defallthroughés true (cert). De manera predeterminada: false (fals).noIndentationBasedFoldinginhabilita el plegat basat en el sagnat dintre del context. Si el plegat basat en el sagnat no està activat, aquest atribut és inútil. Això es defineix en l'element folding del grup general. De manera predeterminada a: false.- L'element
itemDataes troba en el grupitemDatas. Defineix l'estil i els colors de les lletres. Per tant, és possible definir els vostres propis estils i colors. Encara que recomanem utilitzar els estils predeterminats, atès que així l'usuari veurà colors homogenis per als diferents llenguatges. Si bé, algunes vegades no hi ha altres possibilitats i és necessari canviar el color i els atributs de la lletra. Els atributs «name» i «defStyleNum» són necessaris, els altres són opcionals. Els atributs disponibles són: nameestableix el nom del «itemData». Els contexts i les regles utilitzaran aquest nom en els seus atributs attribute per a fer referència a un «itemData».defStyleNumdefineix quin estil s'emprarà de manera predeterminada. Més endavant s'explicaran els estils predeterminats disponibles.colordefineix un color. Els formats vàlids són «#rrggbb» o «#rgb».selColordefineix el color de la selecció.italicsi està a true, el text es mostrarà en cursiva.boldsi està a true, el text es mostrarà en negreta.underlinesi està a true, el text es mostrarà subratllat.strikeOutsi està a true, el text es mostrarà taxat.spellCheckingsi està a true, el text es mostrarà amb la verificació ortogràfica.- L'element
keywordsen el grupgeneraldefineix les propietats «keyword». Els atributs disponibles són: casesensitivepot ser true o false. Si està a true, totes les paraules clau distingiran les majúscules i minúscules.weakDeliminatorés una llista de caràcters que no actuen com a delimitadors de paraules (delimitador feble). Per exemple, el punt«.»és un delimitador de paraula. Si tenim una paraula clau en unalistque conté un punt, tan sols la trobareu si especifiqueu el punt com a delimitador feble.additionalDeliminatordefineix delimitadors addicionals.wordWrapDeliminatordefineix els caràcters al darrere dels quals pot ocórrer un ajust de la línia.Els delimitadors predeterminats i els d'ajust de la línia són els caràcters
.():!+,-<=>%&*/;?[]^{|}~\, espai (« ») i tabulació («\t»).- L'element
commenten el grupcommentsdefineix les propietats dels comentaris emprats per a → , → i → . Els atributs disponibles són: namepot ser singleLine o multiLine. Si escolliu multiLine es necessiten els atributs end i region. Si escolliu singleLine podreu afegir l'atribut opcional position.startdefineix la cadena que s'utilitza per a iniciar un comentari. En C++ seria "/*" en comentaris multilínia. Aquest atribut és requerit per als tipus multiLine i singleLine.enddefineix la cadena utilitzada per a tancar un comentari. En C++ seria "*/". Només està disponible aquest atribut i es necessita per als comentaris del tipus multiLine.regionserà el nom amb el qual es desarà el comentari multilínia. Si assumim que tenim una regió beginRegion="Comentari" ... endRegion="Comentari" en les regles, haureu d'emprar region="Comentari". D'aquesta manera es descomentarà fins i tot si no heu seleccionat tot el text en un comentari multilínia. El cursor només haurà d'estar dins del comentari multilínia. Només està disponible aquest atribut i es necessita per als comentaris del tipus multiLine.positiondefineix on s'insereix el comentari d'una sola línia. De manera predeterminada, el comentari d'una sola línia es col·loca al començament de la línia a la columna 0, però si utilitzeu position="afterwhitespace", el comentari s'insereix a la dreta després dels espais en blanc inicials, abans del primer caràcter que no sigui un espai en blanc. Això és útil per a posar comentaris correctament en llenguatges on la sagnia és important, com el Python o YAML. Aquest atribut és opcional i l'únic valor possible és afterwhitespace. Només està disponible per als tipus singleLine.- L'element
foldingen el grupgeneraldefineix les propietats de plegat del codi. Els atributs disponibles són: indentationsensitivesi està a true, els marcadors de plegat del codi seran afegits al sagnat, com en el llenguatge per a la creació de scripts en Python. Normalment no caldrà establir-lo, ja que de manera predeterminada és false.- L'element
emptyLinepertany al grupemptyLinesdefineix quines línies s'hauran de tractar com a línies buides. Això permet modificar el comportament de l'atribut lineEmptyContext en els elementscontext. Els atributs disponibles són: regexprdefineix una expressió regular que es tractarà com una línia buida. De manera predeterminada, les línies buides no contenen cap caràcter, per tant, això afegirà línies buides addicionals, per exemple, si voleu que les línies amb espais també es consideren com a línies buides. No obstant això, en la majoria de les definicions de la sintaxi no caldrà establir aquest atribut.- L'element
encodingen el grupspellcheckingdefineix una codificació de caràcters per a la verificació ortogràfica. Els atributs disponibles són: char, és un caràcter codificat. Si no s'especifica, la verificació de l'ortografia ignorarà aquesta codificació.stringés una seqüència de caràcters que es codificaran com el caràcter char a la verificació ortogràfica. Per exemple, en el llenguatge LaTeX, la cadena\"{A}representa el caràcterÄ.
Els estils predeterminats ja s'han explicat, a manera de resum: Els estils predeterminats són la lletra i els estils de colors predefinits.
- Estils predeterminats en general:
dsNormal, quan no es requereix un ressaltat especial.dsKeyword, paraules clau integrades.dsFunction, crides a funcions i definicions.dsVariable, si és aplicable: noms de les variables (p. ex., $algunaVar als llenguatges PHP/Perl).dsControlFlow, controla el flux de paraules clau com «if», «else», «switch», «break», «return», «yield»...dsOperator, operadors com + - * / :: < >dsBuiltIn, funcions, classes i objectes integrats.dsExtension, extensions comunes, com les classes de les Qt™ i les funcions/macros en els llenguatges C++ i Python.dsPreprocessor, declaracions del preprocessador o de definicions de macros.dsAttribute, anotacions com «@override» i «__declspec(...)».- Estils predeterminats relacionats amb les cadenes:
dsChar, caràcters sols, com ara «x».dsSpecialChar, caràcters amb un significat especial en cadenes com escapades, substitucions o els operadors d'expressions regulars.dsString, cadenes com «hello world».dsVerbatimString, cadenes literals o sense processar com «raw \backlash» en els llenguatges Perl, CoffeeScript i intèrprets d'ordres, així com «r'\raw'» en llenguatge Python.dsSpecialString, SQL, expressions regulars, documentació HERE, mode matemàtic de LATEX...dsImport, importar, incloure o requerir mòduls.- Estils predeterminats relacionats amb números:
dsDataType, tipus de dades integrats com «int», «void», «u64».dsDecVal, valors decimals.dsBaseN, valors en una base diferent de 10.dsFloat, valors de coma flotant.dsConstant, definicions integrades i definides per l'usuari com PI.- Estils predeterminats relacionats amb la documentació i els comentaris:
dsComment, comentaris.dsDocumentation, «/** Comentaris de documentació */» o «"""cadenes_de_documentació"""».dsAnnotation, ordres de la documentació com «@param», «@brief».dsCommentVar, els noms de les variables utilitzades en les ordres anteriors, com «foobar» a «@param foobar».dsRegionMarker, marcadors de regió com els comentaris «//BEGIN», «//END».- Altres estils predeterminats:
dsInformation, notes i consells com «@note» al doxygen.dsWarning, avisos com «@warning» al doxygen.dsAlert, paraules especials com «Per fer», «TODO», «FIXME», «XXXX».dsError, errors de ressaltat i sintaxi incorrecta.dsOthers, quan res més s'hi ajusti.
Aquesta secció descriu les regles de detecció del ressaltat.
Cada regla pot coincidir en cap o amb diversos caràcters al començament de la cadena amb què es comparen. Si la regla coincideix, als caràcters coincidents se'ls assigna l'estil o attribute definit per la regla, tanmateix, una regla pot demanar que es canviï el context actual.
Una regla té aquest aspecte:
<NomRegla attribute="(identificador)" context="(identificador)" [atributs específics de la regla] />
L'attribute identifica l'estil que utilitzaran els caràcters coincidents per nom, i el context identifica el context a utilitzar des d'aquí.
El context es pot identificar per:
Un identifier, el qual és el nom de l'altre context.
Una order us indica al motor que romandrà en el context actual (
#stay), o que salti al context anterior (#pop). Un context buit o absent és equivalent a#stay.Per a retrocedir més passos, es pot repetir la paraula clau #pop:
#pop#pop#popUna ordre seguida per un signe d'exclamació (!) i un identificador, el qual farà que el motor segueixi primer l'ordre i després passi a l'altre context, p. ex.,
#pop#pop!AltreContext.Podeu apilar diversos contexts amb una marca de repetició (!) i un identificador`, p. ex.
ContextA!ContextB!ContextC. L'últim context de la llista és actiu immediatament; els altres seran accessibles fent servir `#pop`.Un identificador, el qual és un nom de context, seguit de dos coixinets (
##) i un altre identificador, el qual és el nom d'una definició de llenguatge. Aquest nom és similar al que s'utilitza en les reglesIncludeRulesi permet canviar a un context que pertany a una altra definició de ressaltat de la sintaxi, p. ex.,AlgunContext##JavaScript.
Els atributs específics de la regla varien, i es descriuen en les següents seccions.
Atributs comuns
Totes les regles tenen els següents atributs comuns i estan disponibles sempre que apareixen (atributs comuns). Tots els atributs són opcionals.
attribute: Un atribut es correspon a un itemData definit. De manera predeterminada: attribute del context especificat en l'atribut context.
context: Especifica el context al qual canviarà el sistema de ressaltat si les regles coincideixen. De manera predeterminada: #stay.
beginRegion: Inicia un bloc de plegat del codi. De manera predeterminada: unset.
endRegion: Tanca un bloc de plegat del codi. De manera predeterminada: unset.
lookAhead: Si està a true, el sistema de ressaltat no processarà les longituds coincidents. De manera predeterminada: false.
firstNonSpace: Només coincidiran si la cadena no conté un espai en blanc al començament de la línia. De manera predeterminada: false.
column: Només coincideix, si la columna coincideix. De manera predeterminada: unset.
Regles dinàmiques
Algunes regles permeten l'atribut opcional dynamic de tipus lògic que de manera predeterminada és false. Si dynamic està a true, la regla podrà utilitzar arguments que representin el text coincident amb una regla d'una expressió regular que canviï al context actual per al contingut en els atributs string o char. En un string, l'argument %N (a on N és un número) se substituirà amb el corresponent N capturat des de l'expressió regular cridada, començant per 1. En un char l'argument haurà de ser un número N i serà substituït amb el primer caràcter de la corresponent N capturada des de l'expressió regular cridada. Sempre que un regla permeti aquest atribut haurà de contenir un (dynamic).
dinàmic: pot ser (true|false).
Com funciona:
A les expressions regulars de la regla RegExpr, tot el text entre parèntesis (PATRÓ) serà capturat i recordat. Aquestes captures es podran utilitzar en el context al qual es canvia, en les regles amb l'atribut dynamic true, per %N (a String) o N (a char).
És important esmentar que un text capturat en una regla RegExpr només s'emmagatzemarà per al context del canvi, especificat en el seu atribut context.
Suggeriment
Si no s'utilitzen les captures, tant per a les regles dinàmiques com en la mateixa expressió regular, s'han d'utilitzar grups sense captura:
(?:PATRÓ)Els grups lookahead (anticipada) o lookbehind (cerca cap enrere) com
(?=PATRÓ),(?!PATRÓ)(?<=PATRÓ)no seran capturats. Per a obtenir més informació, vegeu la secció sobre expressions regulars.Els grups amb captura es poden utilitzar dins de la mateixa expressió regular, emprant
\Nen lloc de%Nrespectivament. Per a més informació, vegeu Captura del text coincident (referències enrere) a les Expressions regulars.
Exemple 1:
En aquest senzill exemple, el text que coincideix amb l'expressió regular =* serà capturat i inserit dins de %1 a la regla dinàmica. Això permet que el comentari acabi amb la mateixa quantitat de = que al començament. Això coincideix amb el text com: [[ comentari ]], [=[ comentari ]=] o [=====[ comentari ]=====].
A més, les captures només estaran disponibles en el context del canvi Comentari de múltiples línies.
<context name="Normal" attribute="Text normal" lineEndContext="#stay"> <RegExpr context="Comentari de múltiples línies" attribute="Comentari" String="\[(=*)\[" beginRegion="RegionComment"/> </context> <context name="Comentari de múltiples línies" attribute="Comentari" lineEndContext="#stay"> <StringDetect context="#pop" attribute="Comentari" String="]%1]" dynamic="true" endRegion="RegionComment"/> </context>
Exemple 2:
A la regla dinàmica, %1 es correspon amb la captura que coincideix #+, i %2 amb "+. Això coincidirà amb el text de: #label""""dins del context""""#.
Aquestes captures no estaran disponibles en altres contextos, com OtherContext, FindEscapes o AlgunContext.
<context name="AlgunContext" attribute="Normal Text" lineEndContext="#stay"> <RegExpr context="#pop!NamedString" attribute="String" String="(#+)(?:[\w-]|[^[:ascii:]])("+)"/> </context> <context name="NamedString" attribute="String" lineEndContext="#stay"> <RegExpr context="#pop!OtherContext" attribute="String" String="%2(?:%1)?" dynamic="true"/> <DetectChar context="FindEscapes" attribute="Escape" char="\"/> </context>
Exemple 3:
Això coincidirà amb el text com: Class::function<T>( ... ).
<context name="Normal" attribute="Normal Text" lineEndContext="#stay">
<RegExpr context="FunctionName" lookAhead="true"
String="\b([a-zA-Z_][\w-]*)(::)([a-zA-Z_][\w-]*)(?:<[\w\-\s]*>)?(\()"/>
</context>
<context name="FunctionName" attribute="Normal Text" lineEndContext="#pop">
<StringDetect context="#stay" attribute="Class" String="%1" dynamic="true"/>
<StringDetect context="#stay" attribute="Operator" String="%2" dynamic="true"/>
<StringDetect context="#stay" attribute="Function" String="%3" dynamic="true"/>
<DetectChar context="#pop" attribute="Normal Text" char="4" dynamic="true"/>
</context>
Delimitadors locals
Algunes regles permeten els atributs opcionals weakDeliminator i additionalDeliminator, els quals es combinen amb atributs del mateix nom d'etiqueta de keywords. Per exemple, quan '%' és un delimitador feble de keywords, només podrà esdevenir un delimitador de paraula per a una regla posant-lo en el seu atribut additionalDeliminator. Sempre que una regla permeti aquests atributs, contindrà un (delimitadors locals).
weakDeliminator: llista de caràcters que no actuen com a delimitadors de paraula.
additionalDeliminator: defineix delimitadors addicionals.
- DetectChar
Detecta un únic caràcter específic. Normalment s'utilitza per a trobar el final de les cadenes entre cometes.
<DetectChar char="(caràcter)" (atributs comuns) (dinàmic) />
L'atribut
chardefineix el caràcter a comparar.- Detect2Chars
Detecta dos caràcters especificats en l'ordre definit.
<Detect2Chars char="(caràcter)" char1="(caràcter)" (atributs comuns) />
L'atribut
chardefineix el primer caràcter a comparar,char1el segon.Aquesta regla és present per raons històriques i per llegibilitat és preferible utilitzar
StringDetect.- AnyChar
Detecta un caràcter d'un conjunt de caràcters especificats.
<AnyChar String="(cadena)" (atributs comuns) />
L'atribut
Stringdefineix el conjunt de caràcters.- StringDetect
Detecta una cadena exacta.
<StringDetect String="(cadena)" [insensitive="true|false"] (atributs comuns) (dinàmic) />
L'atribut
Stringdefineix la cadena a comparar. L'atributinsensitivepredeterminat ésfalsei es passa a la funció de comparació de la cadena. Si el valor éstruela comparació no distingirà les majúscules i minúscules.- WordDetect
Detectar una cadena exacta requereix límits de paraula com un punt
«.»o un espai en blanc al començament i al final de la paraula. Penseu en\b<cadena>\ben termes d'una expressió regular, però és més ràpid que la reglaRegExpr.<WordDetect String="(cadena)" [insensitive="true|false"] (atributs comuns) (delimitadors locals) />
L'atribut
Stringdefineix la cadena a comparar. L'atributinsensitivepredeterminat ésfalsei es passa a la funció de comparació de la cadena. Si el valor éstruela comparació no distingirà les majúscules i minúscules.Des del: Kate 3.5 (KDE 4.5)
- RegExpr
Cerca la coincidència amb una expressió regular.
<RegExpr String="(cadena)" [insensitive="true|false"] [minimal="true|false"] (atributs comuns) (dinàmic) />
L'atribut
Stringdefineix l'expressió regular.insensitivede manera predeterminada ésfalsei és passada al motor d'expressions regulars.minimalde manera predeterminada ésfalsei és passada al motor d'expressions regulars.Atès que les regles coincideixen amb el començament de la cadena actual, una expressió regular que comenci amb l'accent circumflex (
^) indica que la regla tan sols s'haurà de comparar amb el començament d'una línia.Per a obtenir més informació, vegeu la secció sobre expressions regulars.
- keyword
Detecta una paraula clau des d'una llista especificada.
<keyword String="(nom de la llista)" (atributs comuns) (delimitadors locals) />
L'atribut
Stringidentifica la llista de paraules clau pel seu nom. Haurà d'existir una llista amb aquest nom.El sistema de ressaltat processa les regles de paraules clau d'una manera molt optimitzada. Això fa que sigui una necessitat absoluta que qualsevol paraula clau que coincideixi necessitarà estar envoltada pels delimitadors definits, ja sigui implícitament (els delimitadors predeterminats), o explícitament especificat dins la propietat additionalDeliminator de l'etiqueta keywords.
Si una paraula clau coincideix haurà de contenir un caràcter de delimitador, aquest caràcter respectiu haurà d'afegir-se a la propietat weakDeliminator de l'etiqueta keywords. Aquest caràcter perdrà la seva propietat delimitadora en totes les regles keyword. També és possible utilitzar l'atribut weakDeliminator de la keyword perquè aquesta modificació només s'apliqui a aquesta regla.
- Int
Detecta un nombre enter (com l'expressió regular:
\b[0-9]+).<Int (atributs comuns) (delimitadors locals) />
Aquesta regla no té atributs específics.
- Decimals
Detecta un nombre decimal (com l'expressió regular:
(\b[0-9]+\.[0-9]*|\.[0-9]+)([eE][-+]?[0-9]+)?).<Float (atributs comuns) (delimitadors locals) />
Aquesta regla no té atributs específics.
- HlCOct
Detecta una representació numèrica d'un nombre octal (com l'expressió regular:
\b0[0-7]+).<HlCOct (atributs comuns) (delimitadors locals) />
Aquesta regla no té atributs específics.
- HlCHex
Detecta una representació numèrica d'un nombre hexadecimal (com una expressió regular:
\b0[xX][0-9a-fA-F]+).<HlCHex (atributs comuns) (delimitadors locals) />
Aquesta regla no té atributs específics.
- HlCStringChar
Detecta un caràcter escapat.
<HlCStringChar (atributs comuns) />
Aquesta regla no té atributs específics.
Localitza representacions literals de caràcters que habitualment s'utilitzen en el codi de programació, per exemple
\n(línia nova) o\t(tabulació).Els següents caràcters coincideixen amb la regla si segueixen a una barra inversa (
\):abefnrtv"'?\. A més seran vàlids els nombres hexadecimals escapats com per exemple\xff, i els nombres octals escapats, per exemple\033.- HlCChar
Detecta un caràcter C.
<HlCChar (atributs comuns) />
Aquesta regla no té atributs específics.
Localitza caràcters C tancats en una marca (Exemple:
'c'). La marca pot ser un caràcter simple o un caràcter escapat. Vegeu «HICStringChar» per a localitzar seqüències de caràcters escapats.- RangeDetect
Detecta una cadena amb caràcters d'inici i de final definits.
<RangeDetect char="(caràcter)" char1="(caràcter)" (atributs comuns) />
chardefineix el caràcter que inicia l'interval,char1el caràcter que finalitza l'interval.És molt útil per a detectar, per exemple, petites cadenes entre cometes i similars, però teniu en compte que el motor de ressaltat només pot treballar amb una línia a la vegada, de manera que no es detectaran les cadenes que estiguin dividides en dues línies o més.
- LineContinue
Coincideix amb un caràcter específic al final d'una línia.
<LineContinue (atributs comuns) [char="\"] />
L'atribut
chardefineix un caràcter opcional a comparar, de manera predeterminada és la barra inversa ('\'). Nou des del KDE 4.13.Aquesta regla és pràctica per a canviar el context al final de la línia. Això és necessari per exemple en C/C++ per a continuar macros o cadenes.
- IncludeRules
Inclou regles des d'un altre context o llenguatge/fitxer.
<IncludeRules context="contextlink" [includeAttrib="true|false"] />
L'atribut
contextdefineix el context a incloure.Si és una cadena simple, inclourà totes les regles definides en el context actual, exemple:
<IncludeRules context="anotherContext" />
Si la cadena conté un
##el sistema de ressaltat cercarà un context d'una altra definició del llenguatge amb el nom indicat, per exemple,<IncludeRules context="String##C++" />
inclouria el context String des de la definició de ressaltat en C++.
Si l'atribut
includeAttribestà a true, canvia l'atribut de destinació per un altre de la font. Això és necessari, per exemple, per al treball de comentar, si el text coincideix amb el context inclòs s'utilitzarà un ressaltat diferent que amb el context amfitrió.- DetectSpaces
Detecta els espais en blanc.
<DetectSpaces (atributs comuns) />
Aquesta regla no té atributs específics.
Utilitzeu aquesta regla si sabeu que hi poden haver diversos espais en blanc al davant, per exemple, al començament de les línies sagnades. Aquesta regla ometrà tots els espais en blanc a la vegada, en comptes de comprovar múltiples regles i saltar coincidències.
- DetectIdentifier
Detecta identificadors de cadenes (com l'expressió regular:
[a-zA-Z_][a-zA-Z0-9_]*).<DetectIdentifier (atributs comuns) />
Aquesta regla no té atributs específics.
Utilitzeu aquesta regla per a saltar d'una vegada una cadena de paraula de caràcters, en comptes de comprovar múltiples regles a la vegada i saltar coincidències.
Una vegada que hàgiu entès com funciona el canvi de context serà fàcil escriure definicions de ressaltat. Tot i que haureu de tenir cura de comprovar en quina situació s'hauria de seleccionar una regla. Les expressions regulars són molt potents, però són lentes en comparació amb altres regles. Per això haureu de tenir en compte els següents consells.
Les expressions regulars són fàcils d'emprar, però a vegades hi ha formes molt més ràpides d'obtenir el mateix resultat. Imagineu que només desitgeu localitzar el caràcter
«#»si aquest és el primer caràcter de la línia. Una solució basada en una expressió regular seria quelcom semblant a això:<RegExpr attribute="Macro" context="macro" String="^\s*#" />
Podeu aconseguir el mateix molt més ràpid utilitzant:
<DetectChar attribute="Macro" context="macro" char="#" firstNonSpace="true" />
Si voleu que l'expressió regular localitzi
«^#»també podeu utilitzarDetectCharamb l'atributcolumn="0". L'atributcolumncompta els caràcters, per tant, el tabulador és només un caràcter.A les regles
RegExpr, utilitzeu l'atributcolumn="0"si el patró^PATRÓs'utilitza per a fer coincidir el text amb el començament d'una línia. Això millorarà el rendiment, ja que evitarà cercar coincidències en la resta de les columnes.En les expressions regulars, utilitzeu grups sense captura
(?:PATRÓ)en lloc dels grups amb captura(PATRÓ), si les captures no s'utilitzen per a la mateixa expressió regular o en regles dinàmiques. Això evita emmagatzemar innecessàriament les captures.Podeu canviar de context sense processar els caràcters. Suposeu que voleu canviar de context quan trobeu una cadena
*/, però cal processar aquesta cadena en el següent context. La regla de sota coincidirà, i l'atributlookAheadfarà que es desi la cadena coincident per al següent context.<StringDetect attribute="Comment" context="#pop" String="*/" lookAhead="true" />
Utilitzeu
DetectSpacessi sabeu quants espais en blanc hi ha.Utilitzeu
DetectIdentifieren comptes de l'expressió regular«[a-zA-Z_]\w*».Utilitza els estils predeterminats sempre que es pugui. D'aquesta manera l'usuari es trobarà un entorn familiar.
Mireu altres fitxers XML per a comprovar de quina forma altra gent implementa les regles delicades.
Podeu validar tots els fitxers XML utilitzant l'ordre validatehl.sh mySyntax.xml. El fitxer
validatehl.shusa ellanguage.xsd, els quals estan disponibles al repositori del ressaltat de la sintaxi.Si tot sovint repetiu expressions regulars complexes podeu utilitzar ENTITIES. Exemple:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE language [ <!ENTITY la_meva_ref "[A-Za-z_:][\w.:_-]*"> ]>Ara podeu utilitzar &la_meva_ref; en comptes de l'expressió regular.
A l'editor del Kate, podeu tornar a carregar les sintaxis utilitzant la línia d'ordres integrada (drecera predeterminada
F7) i l'ordre reload-highlighting.Podeu utilitzar la utilitat de línia d'ordres anomenada
ksyntaxhighlighter6(kate-syntax-highlighteren versions anteriors) per a provar una sintaxi i mostrar l'estil i les regions associades amb cada part d'un text.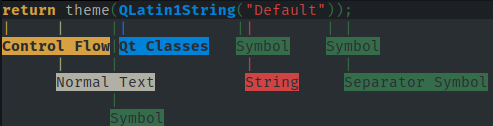
Resultat de ksyntaxhighlighter6 --output-format=ansi --syntax-trace=format test.cpp.
Useu ksyntaxhighlighter6 -h per a més opcions.