Підсвічування синтаксису призначено для автоматично показу тексту у різних стилях і кольорах, залежно від призначення відповідного рядка та файла, з якого взято цей рядок. У початковому коді програми, наприклад, оператори керування може бути показано жирним шрифтом, а типи даних і коментарі — кольором, відмінним від кольору решти тексту. За допомогою підсвічування можна значно покращити зручність читання тексту, а отже підвищити ефективність та продуктивність роботи з цим текстом.

Функція, написана мовою C++, показана з підсвічуванням синтаксису.

Та сама функція, написана мовою C++, без підсвічування.
Ну що, який з двох прикладів зручніше читати?
У KatePart передбачено гнучку, придатну для налаштування і потужну систему підсвічування синтаксичних конструкцій, у стандартному пакунку ви знайдете визначення для широкого спектру мов програмування, написання скриптів та розмітки, а також текстових файлів у інших форматах. Окрім того, ви можете створювати власні визначення за допомогою простих файлів XML.
KatePart автоматично визначатиме належні правила підсвічування синтаксису під час відкриття файла. Дія з визначення відбуватиметься на основі типу MIME файла, який визначатиметься за суфіксом назви файла або, якщо у назві немає суфіксу, за вмістом файла. Якщо, на вашу думку, програма зробила неправильний вибір, ви можете вручну вказати правила підсвічування за допомогою пункту меню → .
Гарнітури шрифту та кольори, які буде використано визначенням підсвічування синтаксису, можна налаштувати на вкладці Стилі підсвічування тексту діалогового вікна налаштування, типами ж MIME та суфіксами назв файлів, для яких буде використано таке підсвічування керує вкладка Режими та типи файлів.
Примітка
Підсвічування можна використовувати для покращення візуального сприйняття тексту, але довірятися підсвічуванню під час перевірки коректності синтаксису тексту не слід. Синтаксична розмітка тексту є непростим завданням, складність якого залежить від формату тексту, — у деяких випадках, автори синтаксичних правил вважають успіхом правильний показ 98% тексту, хоча для того, щоб побачити 2% тексту з неправильним підсвічуванням, вам доведеться скористатися не дуже поширеним стилем.
У цьому розділі ми зосередимося на механізмах, які використовуються для підсвічування синтаксису у KatePart. Відомості з цього розділу призначено для тих користувачів, яким цікаво дізнатися про роботу системи підсвічування синтаксису, або тих користувачів, які бажають змінити або створити нові визначення підсвічування синтаксису.
Під час відкриття файла однією з перших дій, які виконує редактор KatePart, є визначення правил підсвічування синтаксису для цього файла. Під час читання тексту з файла або отримання введених вами рядків система підсвічування синтаксису аналізуватиме текст на основі правил підсвічування синтаксису і позначатиме у показаному тексті позиції початку і завершення різних контекстів і стилів.
Під час введення документа за допомогою клавіатури створений вами текст буде проаналізовано і розмічено на льоту, отже, якщо ви вилучите символ, які система розмітила як початок або завершення певного контексту, стиль сусідніх з поточним фрагментів тексту також змінюватиметься відповідно до зміни контексту.
Визначення синтаксичних правил, які використовуються у системі підсвічування синтаксису KatePart, є файлами XML, у яких містяться
Правила для визначення ролі тексту, впорядковані у контекстні блоки
Списки ключових слів
Визначення елементів стилю
Під час аналізу тексту правила визначення контексту застосовуватимуться у порядку, у якому ці правила було визначено у файлі визначень, — якщо початок поточного рядка відповідає певному правилу, буде використано відповідний контекст. Після цього початкову точку у тексті буде пересунуто у завершальну точку застосування визначеного правила і почнеться новий цикл пошуку відповідників правил в межах контексту, встановленого попереднім правилом.
Правила визначення є основою системи визначення підсвічування. Кожне правило визначається рядком, символом або формальним виразом, з яким порівнюватиметься текст документа. Правилом визначаються відомості, які буде використано під час визначення стилю відповідного фрагмента тексту. Правило може перемкнути поточний контекст системи підсвічування або на явно вказаний у правилі контекст або на попередній контекст, який було використано у тексті.
Правила об’єднуються у контекстні групи. Кожна контекстна група реалізує основні елементи у відповідному форматі файлів, наприклад текстові рядки у лапках або блоки коментарів у файлах кодів програми. За такої структури системи підсвічування можна уникнути потреби у переборі всього набору правил, коли такий перебір не потрібен, а також мати можливість різного трактування деяких послідовностей символів у тексті, залежно від поточного контексту.
Контексти можуть створюватися і динамічно, таким чином забезпечується використання у правилах особливостей даних документа.
У деяких мовах програмування цілі числа обробляються компілятором (програмою, яка перетворює початкові коди програми на бінарний файл програми) у спосіб, відмінний від способу обробки чисел з плаваючою крапкою, також у рядках, взятих у лапки, можуть бути символи зі спеціальним призначенням. У таких випадках було б доцільним виокремити подібні символи, щоб їх простіше було виявити під час читання коду. Отже, навіть якщо ці символи не мають окремого контексту, система підсвічування тексту показати їх так, неначе подібний контекст для них існує, тобто виокремити їх з-поміж навколишнього тексту.
У визначенні синтаксису може бути довільна кількість стилів, достатня для визначення всіх елементів формату тексту, для якого це визначення було створено.
У багатьох форматах існують списки слів, які відповідають певному елементу. Наприклад, у мовах програмування керівні команди складають один елемент, назви типів даних — другий, вбудовані функції мови — третій. Система підсвічування синтаксису KatePart здатна використовувати такі списки для виявлення і позначення слів у тексті з метою підкреслення призначення елементів у текстових форматах.
Якщо ви відкриєте файл кодів мовою C++, Java™ або документ HTML у KatePart, ви переконаєтеся у тому, що, хоча формати цих файлів є різними, а отже у них використовуються різні слова для позначень елементів тексту, кольори, які буде використано програмою будуть тими самими. Причиною цього є існування у KatePart наперед визначеного списку типових стилів, який використовується у окремих визначеннях синтаксису.
Типові стилі спрощують розпізнавання подібних елементів у різних форматах тексту. Наприклад, коментарі передбачено майже у всіх мовах програмування, написання скриптів або мовах розмітки, отже, якщо їх буде показано у однаковому стилі у всіх форматах мов, вам не потрібно буде зупинятися і розмірковувати над тим, як виглядають коментарі у тексті документа.
Підказка
Під час створення всіх стилів визначення синтаксису використовують один з типових стилів. У деякій частині визначень синтаксису використовуються додаткові стилі, яких немає серед типових, отже, якщо ви часто працюєте з файлами у таких форматах, доцільно відкрити діалогове вікно налаштування, щоб подивитися, чи не використовуються для певних елементів однакові стилі. Наприклад, існує лише один типовий стиль для рядків, але, оскільки у мові програмування Perl існує два типи рядків, ви можете налаштувати підсвічування для кожного з цих типів трохи по-різному. Огляд всіх можливих типових стилів буде наведено далі.
У KatePart використовується бібліотека підсвічування синтаксичних конструкцій з KDE Frameworks™. Типово, до бібліотеки підсвічування синтаксичних конструкцій KatePart включено засоби підсвічування коду XML.
Цей розділ присвячено огляду формату XML визначення підсвічування. За допомогою невеличкого прикладу у розділі описано основні компоненти, їх призначення і використання. Далі ми докладно розглянемо правила визначення підсвічування синтаксису.
Формальне визначення, також відоме як XSD, зберігається у сховищі підсвічування синтаксису у файлі language.xsd.
Нетипові файли .xml підсвічування синтаксису зберігаються у org.kde.syntax-highlighting/syntax/ у теці вашого користувача, у підтеці, назву якої можна визначити за допомогою команди qtpaths, зазвичай --paths GenericDataLocation$HOME/.local/share//usr/share/.
Для пакунків Flatpak і Snap місце зберігання даних є різним для різних програм. У пакунках Flatpak нетипові файли XML зберігаються, зазвичай, у $HOME/.var/app/назва-пакунка-flatpak/data/org.kde.syntax-highlighting/syntax/$HOME/snap/назва-пакунка-snap/current/.local/share/org.kde.syntax-highlighting/syntax/
У Windows® ці файли зберігаються у %USERPROFILE%\AppData\Local\org.kde.syntax-highlighting\syntax. %USERPROFILE% зазвичай є скороченням від C:\Users\.користувач
Загалом, для більшості конфігурацій каталогом нетипових файлів XML є такий каталог:
| Для окремого користувача: | |
| Для усіх користувачів? | /usr/share/org.kde.syntax-highlighting/syntax/ |
| Для пакунків Flatpak: | |
| Для пакунків Snap: | |
| У Windows®: | %USERPROFILE%\AppData\Local\org.kde.syntax-highlighting\syntax |
| У macOS® | |
Якщо для якоїсь мови існує декілька файлів, буде завантажено файл із найбільшим значенням атрибута version в елементі language.
Головні розділи файлів визначення підсвічування KatePart
- Файл підсвічування містить заголовок, у якому встановлюється версія XML:
<?xml version="1.0" encoding="UTF-8"?>
- Кореневим елементом файла визначення є елемент
language. Серед можливих атрибутів: Обов’язкові атрибути:
nameвизначає назву мови. Цю назву буде згодом показано у пунктах меню та діалогових вікнах програми.sectionвизначає категорію.extensionsвизначає суфікси назв файлів, на зразок "*.cpp;*.h"versionвизначає поточну модифікацію файла визначень у форматі цілого числа. Кожного разу, коли ви вноситимете зміни до файла визначень правил підсвічування, вам слід збільшувати це число.kateversionвизначає найостаннішу з підтримуваних версій KatePart.Необов’язкові атрибути:
mimetypeприв’язує файли на основі типу MIME.casesensitiveвизначає, чи розрізнятимуться ключові слова за регістром символів, чи ні.priorityпотрібно вказати, якщо у іншому файлі визначення підсвічування використовуються ті самі суфікси файлів. Для підсвічування буде використано правила з вищим пріоритетом.authorповинен містити ім’я і адресу електронної пошти автора.licenseповинен містити назву ліцензії нового файла підсвічування, зазвичай, MIT.styleмає містити дані щодо мови програмування і використовується засобами додавання відступів для атрибутаrequired-syntax-style.indenterвизначає, який із засобів додавання відступів у рядки буде використано типово. Доступні засоби додавання відступів: ada, normal, cstyle, cmake, haskell, latex, lilypond, lisp, lua, pascal, python, replicode, ruby та xml.hiddenвизначає, чи має бути показано назву підсвічування у меню KatePart.Отже, наступний рядок має виглядати десь так:
<language name="C++" version="1" kateversion="2.4" section="Sources" extensions="*.cpp;*.h" />
- Наступним елементом є
highlighting, у цьому елементі міститься необов’язковий елементlistі обов’язкові елементиcontextsіitemDatas. Елементи
listмістять список ключових слів. У цьому випадку ключовими словами будуть class і const. У разі потреби ви можете додати довільну кількість списків.Починаючи з KDE Frameworks™ 5.53, до списку можна включати ключові слова з іншого списку або мови чи файла за допомогою елемента
include. Для відокремлення назви списку та назви визначення мови слід використовувати##у той самий спосіб, що і у правиліIncludeRules. Ця можливість є корисною для уникнення дублювання списків ключових слів, якщо вам потрібно включити ключові слова з іншої мови або файла. Наприклад, у списку othername міститься ключове слово str і усі ключові слова списку types, який належить до мови програмування ISO C++.У елементі
contextsмістяться всі контексти. Типово, першим контекстом є початок діапазону підсвічування. У контексті Normal Text існує два правила: перше визначає список ключових слів з назвою somename і правило для визначення лапок і перемикання контексту на контекст string. Докладніше правила буде розглянуто у наступній главі.Третя частина складається з елемента
itemDatas. У цьому елементі містяться всі кольори і гарнітури шрифтів, потрібні для контекстів і правил. У нашому випадку було використаноitemDataNormal Text, String і Keyword.<highlighting> <list name="somename"> <item>class</item> <item>const</item> </list> <list name="othername"> <item>str</item> <include>types##ISO C++</include> </list> <contexts> <context attribute="Normal Text" lineEndContext="#pop" name="Normal Text" > <keyword attribute="Keyword" context="#stay" String="somename" /> <keyword attribute="Keyword" context="#stay" String="othername" /> <DetectChar attribute="String" context="string" char=""" /> </context> <context attribute="String" lineEndContext="#stay" name="string" > <DetectChar attribute="String" context="#pop" char=""" /> </context> </contexts> <itemDatas> <itemData name="Normal Text" defStyleNum="dsNormal" /> <itemData name="Keyword" defStyleNum="dsKeyword" /> <itemData name="String" defStyleNum="dsString" /> </itemDatas> </highlighting>- Останньою частиною визначення підсвічування є необов’язковий розділ
general. У ньому можуть міститися відомості щодо ключових слів, згортання коду, коментарів, відступів, порожніх рядків та перевірки правопису. У розділі
commentвизначається послідовність символів, за допомогою якої можна додати однорядковий коментар. Крім того, ви можете визначати багаторядкові коментарі за допомогою елемента multiLine з додатковим атрибутом end. Ці визначення буде використано за виконання користувачем дій закоментувати/розкоментувати.У розділі
keywordsвизначається те, чи слід враховувати регістр символів у списку ключових слів, чи ні. Інші атрибути буде описано далі за текстом.В інших розділах,
folding,emptyLinesіspellchecking, зазвичай, потреби немає. Пояснення щодо цих розділів наведено нижче.<general> <comments> <comment name="singleLine" start="#"/> <comment name="multiLine" start="###" end="###" region="CommentFolding"/> </comments> <keywords casesensitive="1"/> <folding indentationsensitive="0"/> <emptyLines> <emptyLine regexpr="\s+"/> <emptyLine regexpr="\s*#.*"/> </emptyLines> <spellchecking> <encoding char="á" string="\'a"/> <encoding char="à" string="\`a"/> </spellchecking> </general> </language>
У цій частині описано всі доступні атрибути для контекстів, itemDatas, ключових слів, коментарів, згортання коду і відступів.
- Елемент
contextналежить до групиcontexts. Цей елемент визначає специфічні для контексту правила, на зразок того, що має трапитися, якщо система підсвічування досягне кінця рядка. Серед можливих атрибутів: name— назва контексту. За допомогою цієї назви правила визначатимуть контекст, на який слід перемкнутися у випадку виявлення відповідника правила.attributeвизначає стиль, який слід використати для символу, якщо не виявлено відповідності жодному правилу або якщо правило не визначає атрибута. У другому випадку буде використано атрибут контексту, який вказано у контексті правила.lineEndContextвизначає контекст, на який має перемкнутися система підсвічування у разі досягнення кінця рядка. Значенням може бути назва іншого контексту,#stayозначатиме, що контекст не слід перемикати (тобто нічого не робити), або#popозначатиме, що слід вийти з контексту. Наприклад, можна скористатися значенням#pop#pop#popдля того, щоб система після виходу піднялася на три контексти вище, або навіть#pop#pop!ІншийКонтекст, щоб піднятися на два контексти вище і перемкнутися на контекст з назвоюІншийКонтекст. Також можна перемкнутися на контекст, який належить визначенню іншої мови, так само, як у правилахIncludeRules, наприклад,ЯкийсьКонтекст##JavaScript. Перемикачі контексту також описано у розділі «Правила визначення способу підсвічування». Типове значення: #stay.lineEmptyContextвизначає контекст, якщо буде знайдено порожній рядок. Номенклатура перемикань контексту є такою самою, як і раніше описано для lineEndContext. Типове значення: #stay.fallthroughContextвказує наступний контекст для перемикання, якщо жодне з правил не є відповідним. Номенклатура перемикань контексту є такою самою, як і раніше описано для lineEndContext. Типове значення: #stay.fallthroughвизначає, чи перемикатиметься система підсвічування на контекст, визначений уfallthroughContext, якщо жодне з правил не буде визнано відповідним. Зауважте, що з версії KDE Frameworks™ 5.62 цей атрибут є застарілим. Замість нього слід використовуватиfallthroughContext, оскільки якщо вказано атрибутfallthroughContext, неявним чином припускатиметься значенняfallthroughрівне true. Типове значення: false.noIndentationBasedFoldingвимикає згортання на основі відступів у контексті. Якщо згортання на основі відступів не увімкнено, цей атрибут не має сенсу. Цей атрибут визначається у елементі folding групи general. Типове значення: false.- Елемент
itemDataзнаходиться у групіitemDatas. За його допомогою визначаються тип шрифту і кольори. Таким чином можна визначати власні типи шрифтів і кольори, але ми рекомендуємо, за можливості, використовувати лише типові стилі так, щоб користувач завжди бачив однакові кольори у файлах різних форматів. Все ж іноді іншого способу не існує, і вам доведеться змінити колір і атрибути шрифту. Обов’язковими атрибутами є name і defStyleNum, інші атрибути є необов’язковими. Серед можливих атрибутів: nameвизначає назву itemData. Цю назву буде використано у контекстах і правилах для посилання на itemData у атрибуті attribute.defStyleNumвизначає, який тип слід використовувати типово. Докладний перелік можливих типових стилів ви знайдете нижче.colorвизначає колір. Можливі формати: '#rrggbb' і '#rgb'.selColorвизначає колір виділеного тексту.italic, якщо має значення true, шрифт буде курсивним.bold, якщо має значення true, шрифт тексту буде напівжирним.underline: якщо цей атрибут має значення true, текст буде підкреслено.strikeOut, якщо цей параметр має значення true, текст буде перекреслено.spellChecking: якщо цей атрибут має значення true, правопис тексту буде перевірено.- Елемент
keywordsу групіgeneralвизначає властивості ключових слів. Серед можливих атрибутів: casesensitive, може приймати значення true або false. Якщо має значення true, пошук ключових слів відбуватиметься з врахуванням регістру символів.weakDeliminator— це список символів, які не є символами відокремлення слів. Наприклад, крапка«.»є символом відокремлення слів. Припустімо тепер, що ключове слово уlistмістить крапку, тоді це слово буде задіяно, лише якщо ви вкажете крапку серед значень цього аргументу.additionalDeliminatorвизначає додаткові символи розмітки.wordWrapDeliminatorвизначає символи, після яких можна розривати рядок.Типовими символами розмітки і символами відокремлення слів є символи
.():!+,-<=>%&*/;?[]^{|}~\, пробіл (' ') і символ табуляції ('\t').- Елемент
commentу групіcommentsвизначає властивості коментаря, які буде використано для дій за пунктами меню → , → and → . Серед доступних атрибутів: name: може мати значення singleLine або multiLine. Якщо буде обрано варіант multiLine, слід буде також вказати атрибути end і region. Якщо ви виберете singleLine, ви зможете додати необов'язковий атрибут position.startвизначає рядок, який використовується для позначення початку коментаря. У C++ цим рядком для багаторядкових коментарів є "/*". Цей атрибут є обов'язковим для типів multiLine і singleLine.endвизначає рядок, яким завершуватиметься коментар. У C++ цим рядком буде "*/". Цей атрибути є доступним лише для коментарів типу multiLine і є для них обов'язковим.Атрибут
regionповинен мати значення назви придатного для згортання багаторядкового коментаря. Припустімо, що у правилах вказано beginRegion="Comment" ... endRegion="Comment", тоді вам слід взяти значення region="Comment". За допомогою цього атрибута можна користуватися дією з розкоментування, навіть якщо було виділено не весь текст багаторядкового коментаря. Потрібно лише, щоб курсор знаходився всередині цього багаторядкового коментаря. Цей атрибут є доступним лише для типу multiLine.positionвизначає місце вставлення однорядкового коментування. Типово, однорядкове коментування буде вставлено на початку рядка у позиції 0, але якщо ви скористаєтеся записом position="afterwhitespace", коментування буде вставлено праворуч після першого пробільного блоку, перед першим непробільним символом. Ця можливість є корисною для мов, де важливими є відступи у рядках, зокрема Python та YAML. Цей атрибут є необов'язковим, його єдиним можливим значенням є afterwhitespace. Цей атрибут є доступним лише для типу singleLine.- Елемент
foldingу групіgeneralпризначено для визначення властивостей згортання коду. Серед можливих атрибутів: indentationsensitive: якщо має значення true, позначки згортання коду буде додано на основі відступів, так, як це робиться у скриптовій мові Python. Зазвичай, вам не потрібно буде встановлювати цей атрибут, оскільки його типовим значенням є false.- Елемент
emptyLineу групіemptyLinesвизначає, які з рядків слід вважати порожніми. За його допомогою можна змінити поведінку атрибута lineEmptyContext в елементахcontext. Наявні атрибути: regexprвизначає формальний вираз, відповідник якого вважатиметься порожнім рядком. Типово, порожні рядки не містять жодних символів, тому цей формальний вираз додає «порожні» рядки, наприклад, якщо ви хочете вважати рядки з пробілів порожніми. Втім, здебільшого, для визначення синтаксису у цьому атрибуті немає потреби.- Елемент
encodingу групіspellcheckingвизначає кодування символів для перевірки правопису. Наявні атрибути: char— кодований символ.string— послідовність символів, яку буде закодовано як символ char при перевірці правопису. Наприклад, якщо виконується обробка коду мовою LaTeX, рядок\"{A}відповідатиме символуÄ.
Ви вже обговорювали типові стилі у короткому резюме: типовими стилями є наперед визначені набори з гарнітур шрифтів та кольорів.
- Загальні типові стилі:
dsNormal, якщо непотрібне спеціальне підсвічування.dsKeyword, вбудовані ключові слова мови.dsFunction, виклики і визначення функцій.dsVariable, якщо застосовне: назви змінних (наприклад $someVar у PHP/Perl).dsControlFlow, ключові слова керування обробкою, зокрема if, else, switch, break, return, yield, ...dsOperator, оператори, зокрема + - * / :: < >dsBuiltIn, вбудовані функції, класи і об’єкти.dsExtension, загальні розширення, зокрема класи Qt™ та функції і макроси у C++ та Python.dsPreprocessor, інструкції препроцесора або визначення макросів.dsAttribute, анотації, зокрема @override та __declspec(...).- Типові стилі, пов’язані із рядками:
dsChar, окремі символи, зокрема 'x'.dsSpecialChar, символи із спеціальним призначенням у рядках, зокрема символи екранування, замінники або оператори формальних виразів.dsString, рядки, зокрема "hello world".dsVerbatimString, буквальні або необроблювані рядки, зокрема «raw \backlash» у Perl, CoffeeScript та командних оболонках, а також r'\raw' у Python.dsSpecialString, SQL, формальні вирази, документація HERE, математичний режим LATEX...dsImport, імпорт, включення або потреба у модулях.- Пов’язані із числами типові стилі:
dsDataType, вбудовані типи даних, наприклад int, void, u64.dsDecVal, десяткові значення.dsBaseN, величини у численні з основою, відмінною від 10.dsFloat, значення із рухомою крапкою.dsConstant, вбудовані та визначені користувачем сталі, наприклад PI.- Типові стилі, пов’язані із коментаріми та документацією:
dsComment, коментарі.dsDocumentation, /** Коментарі у документації */ або """docstrings""".dsAnnotation, команди документації, зокрема @param, @brief.dsCommentVar, назви змінних, використаних у попередніх командах, зокрема «foobar» у @param foobar.dsRegionMarker, позначки області, зокрема //BEGIN, //END у коментарях.- Інші типові стилі:
dsInformation, нотатки і підказки, наприклад @note у doxygen.dsWarning, попередження, наприклад @warning у doxygen.dsAlert, спеціальні слова, наприклад TODO, FIXME, XXXX.dsError, підсвічування помилок та синтаксичних неточностей.dsOthers, якщо інше не є застосовним.
Цей розділ присвячено опису правил визначення синтаксису.
Кожне з правил може відповідати нульовій або більшій кількості символів на початку рядка, у якому шукатиметься відповідник правила. Якщо такий відповідник буде знайдено, знайдені символи визначать стиль або attribute, вказані за допомогою правила, правило також може надіслати системі запит на зміну поточного контексту.
Правило виглядає так:
<НазваПравила attribute="(ідентифікатор)" context="(ідентифікатор)" [специфічні для правила атрибути] />
Значення attribute визначає назву стилю, який буде використано для відповідних символів, а значення context визначає контекст, який слід використовувати, починаючи з цього місця.
context може бути визначено за допомогою:
Ідентифікатора, який є назвою іншого контексту.
Значення порядку, яке повідомляє рушієві, чи слід залишатися у поточному контексті (
#stay), чи слід повернутися до попереднього контексту, використаного у рядку (#pop). Порожній або невизначений контекст означає#stay.Щоб повернутися на декілька рівнів контексту назад, ключове слово #pop можна повторити декілька разів:
#pop#pop#popЗначення порядку, після якого вказано знак оклику (!), та значення ідентифікатора, яке змусить рушій спочатку використати порядок, а потім перемкнутися на інший контекст, наприклад
#pop#pop!OtherContext.Ідентифікатор, який є назвою контексту, за яким вказано два символи решітки (
##) і ще один ідентифікатор, який є назвою визначення мови. Таке іменування є подібним до використаного у правилахIncludeRules. Воно надає вам змогу перемкнутися на контекст, що належить іншому визначення підсвічування синтаксису, наприклад,ЯкийсьКонтекст##JavaScript.
Специфічні для правила атрибути можуть бути різними, їх описано у наступних розділах.
Загальні атрибути
Всі правила мають перелічені нижче атрибути, їх можна вказувати всюди, де ви побачите напис (загальні атрибути) у списку. Усі атрибути є необов’язковими.
attribute: атрибут, що вказує на визначені itemData. Типове значення: attribute з контексту, який вказано в атрибуті context.
context: визначає контекст, на який слід перемкнути систему підсвічування у разі виявлення відповідника правила. Типове значення: #stay.
beginRegion: почати блок згортання коду. Типове значення: unset.
endRegion: закрити блок згортання коду. Типове значення: unset.
lookAhead: якщо має значення true, система підсвічування не оброблятиме довжину відповідника. Типове значення: false.
firstNonSpace: відповідність встановлюватиметься, лише якщо рядок є першою відмінною від пробілів послідовністю символів у рядку тексту. Типове значення: false.
column: збіг буде зареєстровано, якщо збігатиметься рядок. Типове значення: unset.
Динамічні правила
Деякі з правил надають змогу встановлювати додатковий атрибут, dynamic, булівського типу з типовим значенням false. Якщо атрибут dynamic має значення true, у правилі можна використовувати заповнювачі, які позначають текст, знайдений за допомогою правила формального виразу, текст буде перемкнуто у поточний контекст у його атрибутах string або char. У атрибуті string заповнювач %N (де N — ціле число) буде замінено на відповідний елемент N з виклику формального виразу, починаючи з 1. У атрибуті char заповнювач повинен бути числом N, його буде замінено на перший символ відповідного елемента N з виклику формального виразу. Всі правила, які дозволяють використання цього атрибута, буде позначено написом (dynamic).
dynamic: може мати значення (true|false).
Як це працює:
У формальних виразах правил RegExpr засіб обробки захоплює і запам'ятовує увесь текст у простих круглих дужках — (ШАБЛОН). Захоплені фрагменти тексту можна використовувати у контексті, до якого перемикається засіб, у правилах із атрибутом dynamic true для заміни %N (у String) або N (у char).
Важливо пам'ятати, що фрагмент тексту, який захоплено у правилі RegExpr, зберігається лише у перемкнутому контексті, який вказано за допомогою атрибута context елемента.
Підказка
Якщо у запам'ятовуванні фрагментів тексту немає потреби для побудови динамічних правил або самого формального виразу, слід використовувати
групування без захоплення:(?:ШАБЛОН)Захоплення груп із пошуком вперед і пошуком назад, зокрема за допомогою формальних виразів
(?=ШАБЛОН),(?!ШАБЛОН)або(?<=ШАБЛОН), не відбуватиметься. Щоб дізнатися більше, ознайомтеся з розділом Формальні вирази.Захоплені групи можна використовувати у межах того самого формального виразу за допомогою рядка
\Nзамість%N. Щоб дізнатися про це більше, ознайомтеся із розділом Збереження знайденого тексту (зворотні посилання) у главі Формальні вирази.
Приклад 1:
У цьому простому прикладі обробник захоплює текст, який відповідає формальному виразу =*, і вставляє його замість %1 у динамічному правилі. Таким чином можна визначити коментар, який завершується тією самою кількістю символів =, що і починається. Відповідним текстом буде [[ коментар ]], [=[ коментар ]=] та [=====[ коментар ]=====].
Крім того, захоплені дані доступні лише у перемкнутому контексті Multi-line Comment.
<context name="Normal" attribute="Normal Text" lineEndContext="#stay"> <RegExpr context="Multi-line Comment" attribute="Comment" String="\[(=*)\[" beginRegion="RegionComment"/> </context> <context name="Multi-line Comment" attribute="Comment" lineEndContext="#stay"> <StringDetect context="#pop" attribute="Comment" String="]%1]" dynamic="true" endRegion="RegionComment"/> </context>
Приклад 2:
У динамічному правилі %1 відповідає захопленому фрагменту тексту, який відповідає шаблону #+, а %2 — шаблону "+. Отже, відповідний фрагмент тексту буде таким: #мітка""""у контексті""""#.
Захопленими даними не можна буде скористатися у інших контекстах, зокрема OtherContext, FindEscapes або SomeContext.
<context name="SomeContext" attribute="Normal Text" lineEndContext="#stay"> <RegExpr context="#pop!NamedString" attribute="String" String="(#+)(?:[\w-]|[^[:ascii:]])("+)"/> </context> <context name="NamedString" attribute="String" lineEndContext="#stay"> <RegExpr context="#pop!OtherContext" attribute="String" String="%2(?:%1)?" dynamic="true"/> <DetectChar context="FindEscapes" attribute="Escape" char="\"/> </context>
Приклад 3:
Цей запис відповідає тексту, подібному до такого: Class::function<T>( ... ).
<context name="Normal" attribute="Normal Text" lineEndContext="#stay">
<RegExpr context="FunctionName" lookAhead="true"
String="\b([a-zA-Z_][\w-]*)(::)([a-zA-Z_][\w-]*)(?:<[\w\-\s]*>)?(\()"/>
</context>
<context name="FunctionName" attribute="Normal Text" lineEndContext="#pop">
<StringDetect context="#stay" attribute="Class" String="%1" dynamic="true"/>
<StringDetect context="#stay" attribute="Operator" String="%2" dynamic="true"/>
<StringDetect context="#stay" attribute="Function" String="%3" dynamic="true"/>
<DetectChar context="#pop" attribute="Normal Text" char="4" dynamic="true"/>
</context>
Локальні роздільники
У деяких правилах можна скористатися додатковими атрибутами weakDeliminator і additionalDeliminator, які поєднуються із атрибутами із тією самою назвою теґу keywords. Наприклад, якщо '%' є слабким роздільником keywords, він може стати роздільником слів лише для певного правила, якщо його додати до атрибута additionalDeliminator цього правила. Якщо правило дозволяє ці атрибути, воно містить запис (локальні роздільники).
weakDeliminator: список символів, які не є роздільниками слів.
additionalDeliminator: визначає додаткові роздільники.
- DetectChar
Перевірка на рівність одному певному символу. Зазвичай, використовується для пошуку кінця рядків, взятих у лапки.
<DetectChar char="(символ)" (загальні атрибути) (dynamic) />
Атрибут
charвизначає символ, з яким відбуватиметься порівняння.- Detect2Chars
Перевірка на рівність двом певним символам у вказаному порядку.
<Detect2Chars char="(символ)" char1="(символ)" (загальні атрибути) />
Атрибут
charвизначає перший символ для порівняння,char1— другий.Це правило лишилося з історичних міркувань. Для того, щоб зробити читання зручнішим варто користуватися
StringDetect.- AnyChar
Перевірка на рівність одному з символів вказаного набору.
<AnyChar String="(рядок)" (загальні атрибути) />
Атрибут
Stringвизначає набір символів.- StringDetect
Перевірка на рівність вказаному рядку.
<StringDetect String="(рядок)" [insensitive="true|false"] (загальні атрибути) (dynamic) />
Атрибут
Stringвизначає рядок для порівняння. Типовим значенням атрибутаinsensitiveє false, цей атрибут передається функції порівняння рядків. Якщо значенням атрибута буде true, порівняння відбуватиметься без врахування регістру.- WordDetect
Виявити рядок, але з додатковою вимогою щодо меж слів, зокрема крапки,
'.', або пробілу на початку або у кінці слова. Обробка\b<рядок>\bвідбувається подібно до формального виразу, але виконується швидше за обробку правилаRegExpr.<WordDetect String="(рядок)" [insensitive="true|false"] (загальні атрибути) (локальні роздільники) />
Атрибут
Stringвизначає рядок для порівняння. Типовим значенням атрибутаinsensitiveє false, цей атрибут передається функції порівняння рядків. Якщо значенням атрибута буде true, порівняння відбуватиметься без врахування регістру.Починаючи з Kate 3.5 (KDE 4.5)
- RegExpr
Перевірка на збіг з формальним виразом.
<RegExpr String="(рядок)" [insensitive="true|false"] [minimal="true|false"] (загальні атрибути) (dynamic) />
Атрибут
Stringвизначає формальний вираз.Типовим значенням атрибута
insensitiveє false, цей атрибут передається рушію пошуку за формальним виразом.Типовим значенням атрибута
minimalє false, цей атрибут буде передано рушієві пошуку за формальним виразом.Оскільки пошук відповідників для застосування правила завжди відбувається на початку поточного рядка, формальний вираз, що починається з символу каретки (
^) вказує на те, що пошук відповідника правила слід виконувати лише на початку рядка.Щоб дізнатися більше, ознайомтеся з розділом Формальні вирази.
- keyword
Перевірка на рівність ключовому слову з вказаного списку.
<keyword String="(назва списку)" (загальні атрибути) (локальні роздільники) />
Атрибут
Stringвизначає назву списку ключових слів. Список з вказаною назвою має існувати.Система підсвічування обробляє правила ключових слів у дуже оптимізований спосіб. Тому абсолютно необхідно, щоб усі ключові слова, які слід знайти, було обмежено визначеними роздільниками, заздалегідь передбаченими (типовими роздільниками) або явно визначеними у властивості additionalDeliminator теґу keywords.
Якщо ключове слово, яке слід знайти, має містити символ роздільника, відповідний символ слід додати до властивості weakDeliminator теґу keywords. Після цього символ втратить властивість роздільності у всіх правилах keyword. Також можна скористатися атрибутом weakDeliminator теґу keyword так, щоб ці конкретні зміни застосовувалися лише до цього конкретного правила.
- Int
Виявлення цілого числа (формальний вираз:
\b[0-9]+).<Int (загальні атрибути) (локальні роздільники) />
У цього правила немає особливих атрибутів.
- Float
Виявлення числа із рухомою крапкою (формальний вираз:
(\b[0-9]+\.[0-9]*|\.[0-9]+)([eE][-+]?[0-9]+)?).<Float (загальні атрибути) (локальні роздільники) />
У цього правила немає особливих атрибутів.
- HlCOct
Виявлення вісімкового представлення числа (формальний вираз:
\b0[0-7]+).<HlCOct (загальні атрибути) (локальні роздільники) />
У цього правила немає особливих атрибутів.
- HlCHex
Виявлення шістнадцяткового представлення числа (формальний вираз:
\b0[xX][0-9a-fA-F]+).<HlCHex (загальні атрибути) (локальні роздільники) />
У цього правила немає особливих атрибутів.
- HlCStringChar
Перевірка на відповідність символу керівної послідовності.
<HlCStringChar (загальні атрибути) />
У цього правила немає особливих атрибутів.
Перевірка на відповідність символам, які часто використовуються у коді програм, наприклад
\n(перехід на новий рядок) або\t(табуляція).Пошук буде виконуватися за переліченими далі символами, якщо ці символи стоять одразу за зворотною навскісною рискою (
\):abefnrtv"'?\. Крім того, відповідними вважатимуться шістнадцяткові числа, наприклад\xff, і екрановані вісімкові числа, наприклад\033.- HlCChar
Перевірка на відповідність символу C.
<HlCChar (загальні атрибути) />
У цього правила немає особливих атрибутів.
Перевірка на відповідність символам C, взятим у одинарні лапки (Приклад:
'c'). Отже, у таких лапках може бути простий символ або екранований символ. Щоб дізнатися про пошук екранованих послідовностей символів, перегляньте пункт для HlCStringChar.- RangeDetect
Перевірка на відповідність рядку з вказаними початковим і кінцевим символами.
<RangeDetect char="(символ)" char1="(символ)" (загальні атрибути) />
charвизначає символ, який повинен починати діапазон символів,char1— символ, який має завершувати діапазон.Корисно для виявлення, наприклад, невеличких рядків у лапках, але зауважте, що, оскільки рушій підсвічування обробляє за раз лише один рядок, у такий спосіб неможливо знайти рядки у лапках, які розбито між декількома рядками документа.
- LineContinue
Перевірка на відповідність вказаному символу наприкінці рядка.
<LineContinue (загальні атрибути) [char="\"] />
Необов’язковий для встановлення відповідності атрибут
char, типовим значенням є символ зворотної риски ('\'). Впроваджено з KDE 4.13.Це правило корисне для перемикання контексту наприкінці рядка. Це потрібно, зокрема, у коді мовами C/C++ для продовження макросів або рядків.
- IncludeRules
Включити правила з іншого контексту або мови/файла.
<IncludeRules context="посилання на контекст" [includeAttrib="true|false"] />
Атрибут
contextвизначає контекст, який слід включити.Якщо значенням є простий рядок, у поточний контекст буде включено всі визначені правила, наприклад:
<IncludeRules context="anotherContext" />
Якщо у рядку міститься послідовність символів
##, система підсвічування шукатиме контекст у іншому визначенні мови з вказаною назвою. Приклад:<IncludeRules context="String##C++" />
включить контекст String з визначення правил підсвічування для C++.
Якщо атрибут
includeAttribматиме значення true, атрибут призначення буде змінено на атрибут джерела. Це потрібно для того, щоб, наприклад, виконати коментування, якщо текст, що відповідає знайденому контексту, має інше підсвічування, ніж текст у основному контексті.- DetectSpaces
Пошук пробілів.
<DetectSpaces (загальні атрибути) />
У цього правила немає особливих атрибутів.
Цим правилом можна скористатися, якщо вам точно відомо, що перед текстом рядка має бути декілька пробілів, наприклад, на початку рядків з відступом. За допомогою цього правила можна пропустити одразу всі пробіли, замість послідовної перевірки на основі декількох правил, кожне з яких надаватиме змогу відкидати по одному пробілу за один прийом через невідповідність.
- DetectIdentifier
Пошук рядків ідентифікаторів (зокрема формальних виразів:
[a-zA-Z_][a-zA-Z0-9_]*).<DetectIdentifier (загальні атрибути) />
У цього правила немає особливих атрибутів.
Це правило слід використовувати для пропуску рядка з символів, які складають слова, замість послідовної перевірки на основі декількох правил, кожне з яких надаватиме змогу відкидати по одному символу за один прийом через невідповідність.
Після того, як ви зрозумієте роботу інструменту перемикання контексту, ви зможете писати власні визначення підсвічування. Але вам завжди слід з обережністю ставитися до вибору правил. Формальні вирази є дуже потужним, але досить повільним у порівнянні з іншими, інструментом. Отже, скористайтесь наведеними нижче підказками.
Формальними виразами просто користуватися, але часто існує інший, набагато швидший спосіб досягти результату. Припустімо вам потрібно перевірити, чи є символ
'#'першим символом рядка. Вирішення на основі формального виразу має виглядати десь так:<RegExpr attribute="Macro" context="macro" String="^\s*#" />
Того самого результату можна досягти набагато швидше за допомогою такого правила:
<DetectChar attribute="Macro" context="macro" char="#" firstNonSpace="true" />
Якщо вам потрібно знайти формальний вираз
'^#'ви знову ж таки можете скористатися правиломDetectCharз атрибутомcolumn="0". Відлік значення атрибутаcolumnзасновано на кількості символів, отже табуляція вважатиметься лише одним символом.У правилах
RegExprкористуйтеся атрибутомcolumn="0", якщо буде використано шаблон^ШАБЛОНдля встановлення відповідності тексту на початку рядка. У таких спосіб ви пришвидшите обробку, оскільки у засобу обробки не буде потреби у пошуку у решті позицій рядка.У формальних виразах користуйтеся групуванням без захоплення —
(?:ШАБЛОН), замість групування із захопленням —(ШАБЛОН), якщо захоплені дані не буде використано у тому самому формальному виразі або у динамічних правилах. Таким чином, ви уникнете непотрібного зберігання даних.Ви можете перемикати контексти без обробки символів тексту. Припустімо, що вам потрібно перемкнути контекст у разі виявлення рядка
*/, але також слід обробити цей рядок у наступному контексті. Ви можете скористатися наведеним нижче правилом, у якому атрибутlookAheadпризведе до того, що інструмент визначення підсвічування збереже знайдений рядок для обробки у наступному контексті.<StringDetect attribute="Comment" context="#pop" String="*/" lookAhead="true" />
Скористайтеся
DetectSpaces, якщо вам відома точна кількість пробілів.Скористайтеся
DetectIdentifierзамість формального виразу'[a-zA-Z_]\w*'.За можливості, використовуйте типові стилі. Таким чином, ви полегшите користувачеві призвичаювання до середовища.
Зазирайте до інших файлів XML, щоб дізнатися як інші люди реалізують складні правила.
Ви можете перевірити коректність будь-якого файла XML за допомогою команди validatehl.sh mySyntax.xml. Файл
validatehl.shвикористовуєlanguage.xsd. Обидва ці файли зберігаються у сховищі бібліотеки підсвічування синтаксичних конструкцій.Якщо у вашому файлі часто вживаються складні формальні вирази, ви можете скористатися визначенням ENTITIES. Приклад:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE language [ <!ENTITY myref "[A-Za-z_:][\w.:_-]*"> ]>Після такого визначення ви зможете використовувати &myref; замість формального виразу.
У редакторі Kate ви можете перезавантажити синтаксиси за допомогою вбудованого командного рядка (типове скорочення
F7) і команди reload-highlighting.Ви можете скористатися засобом командного рядка із назвою
ksyntaxhighlighter6(kate-syntax-highlighterу старіших версіях) для тестування синтаксису і перегляду стилю та ділянок, які пов'язано із кожною частиною тексту.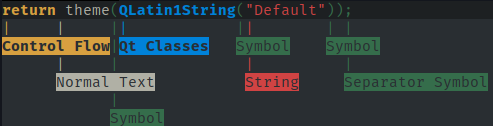
Результат виконання ksyntaxhighlighter6 --output-format=ansi --syntax-trace=format test.cpp.
Скористайтеся командою ksyntaxhighlighter6 -h, щоб дізнатися більше про параметри керування роботою програми.