This configuration page contains all settings regarding the mounting of shares. The settings appearing here are depending on the operation system you are using.
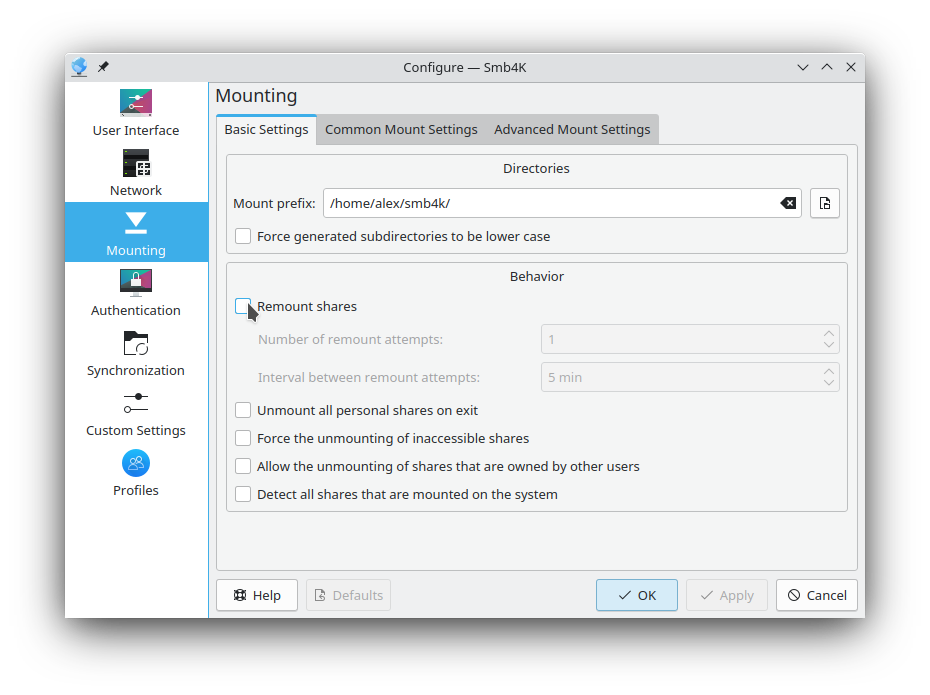
The settings in this tab are the same for all supported operating systems.
This is the base folder (mount prefix) where Smb4K will mount the remote shares. It can be changed by using the URL requester (Click the button with the folder icon.) or by directly entering the new path into the text box. Path variables like
$HOMEare recognized.Default:
$HOME/smb4k/All subdirectories that are created by Smb4K below the mount prefix will be lower case.
Default: not selected
Remount all your shares that were mounted when you exited the program or changed a profile. If the remounting of a share fails, Smb4K will retry the next time it is started. Shares that were mounted by other users are ignored.
Default: not selected
- Number of remount attempts
Set the number of attempts that are made to remount shares before Smb4K gives up.
Default: 1
- Interval between remount attempts
Set the time that elapses between attempts to remount shares.
Default: 5 min
Unmount all shares that belong to you when the program exits. Shares that are owned by other users are ignored.
Default: not selected
Force unmounting of inaccessible shares (Linux® only). In case a share is inaccessible, a lazy unmount is performed. Before the actual unmounting is done, a warning dialog is shown asking to approve the unmount.
Default: not selected
This option will allow you to unmount shares that were mounted by other users.
USE WITH EXTREME CAUTION!
Default: not selected
You will not only see the shares that were mounted and are owned by you, but also all other mounts using the SMBFS (BSD) and CIFS (Linux®) file system that are present on the system.
Default: not selected
The Common Mount Settings tab is only available under Linux® and the listed options refer to the mount.cifs(8) / mount.smb3(8) command. The settings present under BSD can be found in the Mount Settings (BSD only) section.
The write access to a share can be determined here. This option is independent of the file mask and the folder mask settings above. Available options are:
Option:
rwMount the share read-write.
Option:
roMount the share read-only.
Default: not selected;
Option:
iocharset=CHARSETSets the character set used by the client side (i.e. your computer) to one of the following:
Default character set used by the client's kernel. In this case the
iocharsetoption is omitted from the command line.ISO/IEC 8859-1:1998. This character-encoding scheme is used throughout the Americas, Western Europe, Oceania, and much of Africa.
ISO/IEC 8859-2:1999. It is informally referred to as "Latin-2". It is generally intended for Central or "Eastern European" languages that are written in the Latin script.
ISO/IEC 8859-3:1999. It is informally referred to as Latin-3 or South European. It was designed to cover Turkish, Maltese and Esperanto, though the introduction of ISO/IEC 8859-9 superseded it for Turkish.
ISO/IEC 8859-4:1998. It is informally referred to as Latin-4 or North European. It was designed to cover Estonian, Latvian, Lithuanian, Greenlandic, and Sami. It has been largely superseded by ISO/IEC 8859-10 and Unicode.
ISO/IEC 8859-5:1999. It is informally referred to as Latin/Cyrillic. It was designed to cover languages using a Cyrillic alphabet such as Bulgarian, Belarusian, Russian, Serbian and Macedonian but was never widely used.
ISO/IEC 8859-6:1999. It is informally referred to as Latin/Arabic. It was designed to cover Arabic.
ISO/IEC 8859-7:2003. It is informally referred to as Latin/Greek. It was designed to cover the modern Greek language.
ISO/IEC 8859-8:1999. It is informally referred to as Latin/Hebrew. ISO/IEC 8859-8 covers all the Hebrew letters, but no Hebrew vowel signs.
ISO/IEC 8859-9:1999. It is informally referred to as Latin-5 or Turkish. It was designed to cover the Turkish language, designed as being of more use than the ISO/IEC 8859-3 encoding.
ISO/IEC 8859-13:1998. It is informally referred to as Latin-7 or Baltic Rim. It was designed to cover the Baltic languages, and added characters used in the Polish language missing from the earlier encodings ISO 8859-4 and ISO 8859-10. Unlike these two, it does not cover the Nordic languages.
ISO/IEC 8859-14:1998. It is informally referred to as Latin-8 or Celtic. It was designed to cover the Celtic languages, such as Irish, Manx, Scottish Gaelic, Welsh, Cornish, and Breton.
ISO/IEC 8859-15:1999. It is informally referred to as Latin-9 (and for a while Latin-0). It is similar to ISO 8859-1, and thus also intended for “Western European” languages, but replaces some less common symbols with the euro sign and some letters that were deemed necessary.
Unicode (or Universal Coded Character Set) Transformation Format – 8-bit. UTF-8 is used by many Linux® distributions as default character set, and is, in addition, by far the most common encoding for the World Wide Web.
KOI8-R (RFC 1489) is an 8-bit character encoding, derived from the KOI-8 encoding by the programmer Andrei Chernov in 1993 and designed to cover Russian, which uses a Cyrillic alphabet.
KOI8-U (RFC 2319) is an 8-bit character encoding, designed to cover Ukrainian, which uses a Cyrillic alphabet.
KOI8-RU is an 8-bit character encoding, designed to cover Russian, Ukrainian, and Belarusian which use a Cyrillic alphabet.
Windows-1251 is an 8-bit character encoding, designed to cover languages that use the Cyrillic script such as Russian, Bulgarian, Serbian Cyrillic and other languages. In Linux, the encoding is known as cp1251.
GB/T 2312-1980 is a key official character set of the People's Republic of China, used for Simplified Chinese characters. GB2312 is the registered internet name for EUC-CN, which is its usual encoded form. GB/T 2312-1980 has been superseded by GBK and GB18030, which include additional characters, but GB/T 2312 remains in widespread use as a subset of those encodings.
Big-5 or Big5 is a Chinese character encoding method used in Taiwan, Hong Kong, and Macau for traditional Chinese characters. The People's Republic of China (PRC), which uses simplified Chinese characters, uses the GB 18030 character set instead.
EUC-JP is a variable-width encoding used to represent the elements of three Japanese character set standards, namely JIS X 0208, JIS X 0212, and JIS X 0201.
EUC-KR is a variable-width encoding to represent Korean text using two coded character sets, KS X 1001 (formerly KS C 5601) and either ISO 646:KR (KS X 1003, formerly KS C 5636) or US-ASCII, depending on variant. KS X 2901 (formerly KS C 5861) stipulates the encoding and RFC 1557 dubbed it as EUC-KR.
Thai Industrial Standard 620-2533, commonly referred to as TIS-620, is the most common character set and character encoding for the Thai language.
Default: not selected; CHARSET:
Option:
port=PORTSets the port number that is used by mount.cifs(8) when mounting a remote share. The default port number (445) should work for all modern operating systems. If you experience problems, try setting the port number to 139. If the problems only occur with a few hosts, it is recommended to leave this option untouched and to use the Custom Settings editor to define individual port numbers for the problematic hosts.
Default: not selected; PORT: 445
Option: none
Most versions of Samba support the CIFS Unix or POSIX extensions. For these servers, some options are not needed, because the right values are negotiated during the mount process. For other servers, you might want to uncheck this option, so that predefined values can be passed to the server. Please note that if your computer is located in a Windows® dominated network neighborhood with only a few Samba servers, you can safely uncheck this option and define custom settings for the Samba servers.
In case you uncheck this option, consider to switch on permission checks under Advanced Mount Settings.
Default: selected
Option:
uid=UIDSets the owner of the files and directories on the file system. By default, your UID is used. To change the UID, press the search button and choose one from the drop down menu.
In case the support for the CIFS Unix extensions is selected, this setting is disabled.
Default: selected; UID: your UID
Option:
uid=GIDSets the group that owns the files and directories on the file system. By default, your GID is used. To change the GID, press the search button and choose one from the drop down menu.
In case the support for the CIFS Unix extensions is selected, this setting is disabled.
Default: selected; GID: your GID
Option:
file_mode=ARGSets the permissions that are applied to files. The value is given in octal and has to have 4 digits. To learn more about the file mode (file_mode), you should read the mount(8) and umask(2) manual pages.
In case the support for the CIFS Unix extensions is selected, this setting is disabled.
Default: selected; ARG: 0755
Option:
dir_mode=ARGSets the permissions that are applied to directories. The value is given in octal and has to have 4 digits. To learn more about the directory mode (dir_mode), you should read the mount(8) and umask(2) manual pages.
In case the support for the CIFS Unix extensions is selected, this setting is disabled.
Default: selected; ARG: 0755
The Advanced Mount Settings tab is only available under Linux® and the listed options refer to the mount.cifs(8) / mount.smb3(8) command. The settings present under BSD can be found in the Mount Settings (BSD only) section.
Option:
forceuidInstruct the client (i.e. your side) to ignore any user ID (UID) provided by the server for files and directories and to always assign the owner to be the value of the transmitted UID.
Default: not selected
Option:
forcegidInstruct the client (i.e. your side) to ignore any group ID (GID) provided by the server for files and directories and to always assign the owner to be the value of the transmitted GID.
Default: not selected
Option:
permornopermThe client side checks if you have the correct UID and GID to manipulate files and directories on the share. This is in addition to the normal ACL check on the target machine done by the server software. You most definitely want to switch this feature off, if the server(s) support the CIFS Unix extensions and you are, hence, not allowed to fully access the share.
Default: not selected
Option:
setuidsornosetuidsIf the CIFS Unix extensions are negotiated with the server the client side will attempt to set the effective UID and GID of the local process on newly created files, directories, and devices. If this feature is turned off, the default UID and GID defined for the share will be used. It is recommended that you read the manual page of mount.cifs(8) before you change this setting.
Default: not selected
Option:
serverinoornoserverinoUse inode numbers (unique persistent file identifiers) returned by the server instead of automatically generating temporary inode numbers on the client side. This parameter has no effect if the server does not support returning inode numbers or similar. It is recommended that you read the manual page of mount.cifs(8) before you change this setting.
Default: selected
Option:
mapcharsornomapcharsTranslate six of the seven reserved characters (not backslash, but including the colon, question mark, pipe, asterisk, greater than, and less than characters) to the remap range (above 0xF000), which also allows the client side to recognize files created with such characters by Windows®’s POSIX emulation. This can also be useful when mounting to most versions of Samba. This has no effect if the server does not support Unicode.
Default: not selected
Option:
nobrlDo not send byte range lock requests to the server. This is necessary for certain applications that break with cifs style mandatory byte range locks (and most cifs servers do not yet support requesting advisory byte range locks).
Default: not selected
Option:
vers=VERSDefine which version of the SMB protocol is to be used. Normally, this option does not need to be enabled because the protocol version is negotiated between the client and the server.
The following values are allowed:
This causes mount.cifs(8) to use the classic CIFS/SMBv1 protocol.
This causes mount.cifs(8) to use the SMBv2.002 protocol. This was initially introduced in Microsoft® Windows® Vista Service Pack 1 and Windows® Server 2008.
Please note that the initial release version of Microsoft® Windows® Vista spoke a slightly different dialect (2.000) that is not supported.
This causes mount.cifs(8) to use the SMBv2.1 protocol that was introduced in Microsoft® Windows® 7 and Windows® Server 2008R2.
This causes mount.cifs(8) to use the SMBv3.0 protocol that was introduced in Microsoft® Windows® 8 and Windows® Server 2012.
This causes mount.cifs(8) to use the SMBv3.0.2 protocol that was introduced in Microsoft® Windows® 8.1 and Windows® Server 2012R2.
This causes mount.cifs(8) to use the SMBv3.1.1 protocol that was introduced in Microsoft® Windows® Server 2016.
This causes mount.cifs(8) to use the SMBv3.0 protocol version and above.
This causes mount.cifs(8) to try to negotiate the highest SMBv2+ version supported by both the client and server.
Default: not selected; VERS:
Option:
cache=ARGDefine how read and write requests are handled. In case you choose to not cache file data at all, the client never utilizes the cache for normal reads and writes. It always accesses the server directly to satisfy a read or write request. If you choose to follow the CIFS/SMB2 protocol strictly, the cache is only trusted if the client holds an oplock. If the client does not hold an oplock, then the client bypasses the cache and accesses the server directly to satisfy a read or write request. Choosing to allow loose caching semantics can sometimes provide better performance on the expense of cache coherency. This option might cause data corruption, if several clients access the same set of files on the server at the same time. Because of this, the strict cache mode is recommended.
The following values are allowed:
This causes mount.cifs(8) to not cache file data at all.
This causes mount.cifs(8) to follow the CIFS/SMB2 protocol strictly.
This causes mount.cifs(8) to allow loose caching semantics.
Default: not selected; ARG:
Security mode. To be able to use this option, the CIFS kernel module 1.40 or later is needed.
The allowed values are:
The
sec=nonecommand line argument is used. This causes mount.cifs(8) to attempt to connect as a null user (no name).The
sec=krb5command line argument is used. This causes mount.cifs(8) to use Kerberos version 5 authentication.The
sec=krb5icommand line argument is used. This causes mount.cifs(8) to use Kerberos version 5 authentication and force packet signing.The
sec=ntlmcommand line argument is used. This causes mount.cifs(8) to use NTLM password hashing. Up to Linux® kernel version 3.8 this is the default setting.The
sec=ntlmicommand line argument is used. This causes mount.cifs(8) to use NTLM password hashing and force packet signing.The
sec=ntlmv2command line argument is used. This causes mount.cifs(8) to use NTLMv2 password hashing.The
sec=ntlmv2icommand line argument is used. This causes mount.cifs(8) to use NTLMv2 password hashing and force packet signing.The
sec=ntlmsspcommand line argument is used. This causes mount.cifs(8) to use NTLMv2 password hashing encapsulated in a Raw NTLMSSP message. Since Linux® kernel version 3.8 this is the default setting.The
sec=ntlmsspcommand line argument is used. This causes mount.cifs(8) to use NTLMv2 password hashing encapsulated in a Raw NTLMSSP message and force packet signing.
Default: not selected;
Define additional options for use with mount.cifs(8). Clicking the edit button to the right of the line edit opens an input dialog where the options have to be provided in a comma-separated list. After clicking in the input dialog, the options will be checked against a whitelist. All valid entries are accepted and entered into to line edit.
Default: not selected; empty
The Mount Settings tab is only available under FreeBSD, NetBSD and DragonFly BSD. The settings present under Linux® can be found in the Common Mount Settings (Linux® only) and Advanced Mount Settings (Linux® only) sections.
Sets the owner of the files and directories on the file system. By default, your UID is used. To change the UID, press the search button and choose one from the drop down menu.
Default: your UID
Sets the group that owns the files and directories on the file system. By default, your GID is used. To change the GID, press the search button and choose one from the drop down menu.
Default: your GID
Sets the permissions that are applied to files. The value is given in octal and has to have 4 digits. To learn more about the file mode, you should read the mount_smbfs(8) and umask(2) manual pages.
Default: 0755
Sets the permissions that are applied to directories. The value is given in octal and has to have 4 digits. To learn more about the directory mode (dir_mode), you should read the mount_smbfs(8) and umask(2) manual pages.
Default: 0755
Use the specified local and server's character sets.
Default: not selected
Use this character set for the client side. These character sets are available:
Default character set used by the client's kernel.
ISO/IEC 8859-1:1998. This character-encoding scheme is used throughout the Americas, Western Europe, Oceania, and much of Africa.
ISO/IEC 8859-2:1999. It is informally referred to as "Latin-2". It is generally intended for Central or "Eastern European" languages that are written in the Latin script.
ISO/IEC 8859-3:1999. It is informally referred to as Latin-3 or South European. It was designed to cover Turkish, Maltese and Esperanto, though the introduction of ISO/IEC 8859-9 superseded it for Turkish.
ISO/IEC 8859-4:1998. It is informally referred to as Latin-4 or North European. It was designed to cover Estonian, Latvian, Lithuanian, Greenlandic, and Sami. It has been largely superseded by ISO/IEC 8859-10 and Unicode.
ISO/IEC 8859-5:1999. It is informally referred to as Latin/Cyrillic. It was designed to cover languages using a Cyrillic alphabet such as Bulgarian, Belarusian, Russian, Serbian and Macedonian but was never widely used.
ISO/IEC 8859-6:1999. It is informally referred to as Latin/Arabic. It was designed to cover Arabic.
ISO/IEC 8859-7:2003. It is informally referred to as Latin/Greek. It was designed to cover the modern Greek language.
ISO/IEC 8859-8:1999. It is informally referred to as Latin/Hebrew. ISO/IEC 8859-8 covers all the Hebrew letters, but no Hebrew vowel signs.
ISO/IEC 8859-9:1999. It is informally referred to as Latin-5 or Turkish. It was designed to cover the Turkish language, designed as being of more use than the ISO/IEC 8859-3 encoding.
ISO/IEC 8859-13:1998. It is informally referred to as Latin-7 or Baltic Rim. It was designed to cover the Baltic languages, and added characters used in the Polish language missing from the earlier encodings ISO 8859-4 and ISO 8859-10. Unlike these two, it does not cover the Nordic languages.
ISO/IEC 8859-14:1998. It is informally referred to as Latin-8 or Celtic. It was designed to cover the Celtic languages, such as Irish, Manx, Scottish Gaelic, Welsh, Cornish, and Breton.
ISO/IEC 8859-15:1999. It is informally referred to as Latin-9 (and for a while Latin-0). It is similar to ISO 8859-1, and thus also intended for “Western European” languages, but replaces some less common symbols with the euro sign and some letters that were deemed necessary.
Unicode (or Universal Coded Character Set) Transformation Format – 8-bit. UTF-8 is used by many Linux® distributions as default character set, and is, in addition, by far the most common encoding for the World Wide Web.
KOI8-R (RFC 1489) is an 8-bit character encoding, derived from the KOI-8 encoding by the programmer Andrei Chernov in 1993 and designed to cover Russian, which uses a Cyrillic alphabet.
KOI8-U (RFC 2319) is an 8-bit character encoding, designed to cover Ukrainian, which uses a Cyrillic alphabet.
KOI8-RU is an 8-bit character encoding, designed to cover Russian, Ukrainian, and Belarusian which use a Cyrillic alphabet.
Windows-1251 is an 8-bit character encoding, designed to cover languages that use the Cyrillic script such as Russian, Bulgarian, Serbian Cyrillic and other languages. In Linux, the encoding is known as cp1251.
GB/T 2312-1980 is a key official character set of the People's Republic of China, used for Simplified Chinese characters. GB2312 is the registered internet name for EUC-CN, which is its usual encoded form. GB/T 2312-1980 has been superseded by GBK and GB18030, which include additional characters, but GB/T 2312 remains in widespread use as a subset of those encodings.
Big-5 or Big5 is a Chinese character encoding method used in Taiwan, Hong Kong, and Macau for traditional Chinese characters. The People's Republic of China (PRC), which uses simplified Chinese characters, uses the GB 18030 character set instead.
EUC-JP is a variable-width encoding used to represent the elements of three Japanese character set standards, namely JIS X 0208, JIS X 0212, and JIS X 0201.
EUC-KR is a variable-width encoding to represent Korean text using two coded character sets, KS X 1001 (formerly KS C 5601) and either ISO 646:KR (KS X 1003, formerly KS C 5636) or US-ASCII, depending on variant. KS X 2901 (formerly KS C 5861) stipulates the encoding and RFC 1557 dubbed it as EUC-KR.
Thai Industrial Standard 620-2533, commonly referred to as TIS-620, is the most common character set and character encoding for the Thai language.
Default:
Use this character set for the server side. These character sets are available:
Default character set used by the server.
Code page 437 is the character set of the original IBM PC (personal computer). It is also known as CP437, OEM-US, OEM 437, PC-8, or DOS Latin US. The set includes all printable ASCII characters, extended codes for accented letters (diacritics), some Greek letters, icons, and line-drawing symbols.
Code page 720 is a code page used to write Arabic in Egypt, Iraq, Jordan, Saudi Arabia, and Syria.
Code page 737 is a code page used to write the Greek language in Greece.
Code page 775 is a code page used to write the Estonian, Lithuanian and Latvian languages.
Code page 850 is a code page used in Western Europe.
Code page 852 is a code page used to write Central European languages that use Latin script (such as Bosnian, Croatian, Czech, Hungarian, Polish, Romanian, Serbian, Slovak or Slovene).
Code page 855 is a code page used to write Cyrillic script. Code page 872 is the euro currency update of code page 855.
Code page 857 is a code page used in Turkey to write Turkish. It is based on code page 850, but with many changes. It includes all characters from ISO 8859-9.
Code page 858 is a code page used to write Western European languages. Like code page 850, Code page 858 supports the entire repertoire of ISO 8859-1, but in a different arrangement.
Code page 860 is a code page used in Portugal to write Portuguese, and it is also suitable to write Spanish and Italian.
Code page 861 is a code page used in Iceland to write the Icelandic language (as well as other Nordic languages).
Code page 862 is a code page in Israel for Hebrew.
Code page 863 is a code page used in Canada to write French (mainly in Quebec) although it lacks some letters.
Code page 864 is a code page used to write Arabic in Egypt, Iraq, Jordan, Saudi Arabia, and Syria.
Code page 865 is a code page used in Denmark and Norway to write Nordic languages (except Icelandic, for which code page 861 is used).
Code page 866 is a code page used in Russia to write Cyrillic script.
Code page 869 is a code page used to write Greek language.
Code page 874, also known as Code page 9066, is used to write the Thai language.
Code page 932 is the Microsoft® Windows® code page for the Japanese language, which is an extended variant of the Shift JIS Japanese character encoding.
Code page 936 is the Microsoft® Windows® code page for simplified Chinese.
Code page 949 is the Microsoft® Windows® code page for the Korean language.
Code page 950 is the Microsoft® Windows® code page for Traditional Chinese.
Code page 1250 is a Microsoft® Windows® code page to represent texts in Central European and Eastern European languages that use Latin script, such as Polish, Czech, Slovak, Hungarian, Slovene, Bosnian, Croatian, Serbian (Latin script), Romanian (before 1993 spelling reform) and Albanian. It may also be used with the German language.
Code page 1251 is a Microsoft® Windows® code page designed to cover languages that use the Cyrillic script such as Russian, Bulgarian, Serbian Cyrillic, and other languages.
Code page 1252 is a Microsoft® Windows® code page used for English and many European languages including Spanish, French, and German.
Code page 1253 is a Microsoft® Windows® code page used to write modern Greek. It is not capable of supporting the older polytonic Greek.
Code page 1254 is a Microsoft® Windows® code page used to write Turkish.
Code page 1255 is a Microsoft® Windows® code page used to write Hebrew.
Code page 1256 is a Microsoft® Windows® code page write Arabic (and possibly some other languages that use Arabic script, like Persian and Urdu).
Code page 1257 is a Microsoft® Windows® code page to support the Estonian, Latvian and Lithuanian languages.
Code page 1258 is a Microsoft® Windows® code page to represent Vietnamese texts. It makes use of combining diacritical marks.
Unicode is an information technology standard for the consistent encoding, representation, and handling of text expressed in most of the world's writing systems.
Default: default